
Figure 1: A trading signal produced in iMetrica for the daily price index of GOOG (Google) using the log-returns of GOOG and AAPL (Apple) as the explanatory data, The blue-pink line represents the account wealth over time, with a 89 percent return on investment in 16 months time (GOOG recorded a 23 percent return during this time). The green line represents the trading signal built using the MDFA module using the hierarchy of parameters described in this article. The gray line is the log price of GOOG from June 6 2011 to November 16 2012.
In any computational method for constructing binary buy/sell signals for trading financial assets, most certainly a plethora of parameters are involved and must be taken into consideration when computing and testing the signals in-sample for their effectiveness and performance. As traders and trading institutions typically rely on different financial priorities for navigating their positions such as risk/reward priorities, minimizing trading costs/trading frequency, or maximizing return on investment , a robust set of parameters for adjusting and meeting the criteria of any of these financial aims is needed. The parameters need to clearly explain how and why their adjustments will aid in operating the trading signal to their goals in mind. It is my strong belief that any computational paradigm that fails to do so should not be considered a candidate for a transparent, robust, and complete method for trading financial assets.
In this article, we give an in-depth look at the hierarchy of financial trading parameters involved in building financial trading signals using the powerful and versatile real-time multivariate direct filtering approach (MDFA, Wildi 2006,2008,2012), the principle method used in the financial trading interface of iMetrica. Our aim is to clearly identify the characteristics of each parameter involved in constructing trading signals using the MDFA module in iMetrica as well as what effects (if any) the parameter will have on building trading signals and their performance.
With the many different parameters at one’s disposal for computing a signal for virtually any type of financial data and using any financial priority profile, naturally there exists a hierarchy associated with these parameters that all have well-defined mathematical definitions and properties. We propose a categorization of these parameters into three levels according to the clarity on their effect in building robust trading signals. Below are the four main control panels used in the MDFA module for the Financial Trading Interface (shown in Figure 1). They will be referenced throughout the remainder of this article.

Figure 2: The interface for controlling many of the parameters involved in MDFA. Adjusting any of these parameters will automatically compute the new filter and signal output with the new set of parameters and plot the results on the MDFA module plotting canvases.

Figure 3: The main interface for building the target symmetric filter that is used for computing the real-time (nonsymmetric) filter and output signal. Many of the desired risk/reward properties are controlled in this interface. One can control every aspect of the target filter as well as spectral densities used to compute the optimal filter in the frequency domain.

Figure 4: The main interface for constructing Zero-Pole Combination filters, the original paradigm for real-time direct filtering. Here, one can control all the parameters involved in ZPC filtering, visualize the frequency domain characteristics of the filter, and inject the filter into the I-MDFA filter to create “hybrid” filters.

Figure 5: The basic trading regulation parameters currently offered in the Financial Trading Interface. This panel is accessed by using the Financial Trading menu at the top of the software. Here, we have direct control over setting the trading frequency, the trading costs per transaction, and the risk-free rate for computing the Sharpe Ration, all controlled by simply sliding the bars to the desired level. One can also set the option to short sell during the trading period (provided that one is able to do so with the type of financial asset being traded).
The Primary Parameters:
- Trading Frequency. As the title entails, the trading frequency governs how often buy/sell signal will occur during the span of the trading horizon. Regardless of minute data, hourly data, or daily data, the trading frequency regulates when trades are signaled and is also a key parameter when considering trading costs. The parameter that controls the trading frequency is defined by the cutoff frequency in the target filter of the MDFA and is regulated in either the Target Filter Design interface (see Figure 3) or, if one is not accustomed to building target filters in MDFA, a simpler parameter is given in the Trading Parameter panel (see Figure 5). In Figure 3, the pass-band and stop-band properties are controlled by any one of the sliding scrollbars. The design of the target filter is plotted in the Filter Design canvas (not shown).
- Timeliness of signal. The timeliness of the signal controls the quality of the phase characteristics in the real-time filter that computes the trading signal. Namely, it can control how well turning points (momentum changes) are detected in the financial data while minimizing the phase error in the filter. Bad timeliness properties will lead to a large delay in detecting up/downswings in momentum. Good timeliness properties lead to anticipated detection of momentum in real-time. However, the timeliness must be controlled by smoothness, as too much timeliness leads to the addition of unwanted noise in the trading signal, leading to unnecessary unwanted trades. The timeliness of the filter is governed by the
parameter that controls the phase error in the MDFA optimization. This is done by using the sliding scrollbar marked
- Smoothness of signal. The smoothness of the signal is related to how well the filter has suppressed the unwanted frequency information in the financial data, resulting in a smoother trading signal that corresponds more directly to the targeted signal and trading frequency. A signal that has been submitted to too much smoothing however will lose any important timeliness advantages, resulting in delayed or no trades at all. The smoothness of the filter can be adjusted through using the
parameter that controls the error in the stop-band between the targeted filter and the computed concurrent filter. The smoothness parameter is found on the Real-Time Filter Design interface in the sliding scrollbar marked
(see Figure 2) and in the sliding scrollbar marked
- Quantization of information. In this sense, the quantization of information relates to how much past information is used to construct the trading signal. In MDFA, it is controlled by the length of the filter
and is found on the Real-Time Filter Design interface (see Figure 2). In theory, as the filter length
As you might have suspected, there exists a so-called “uncertainty principle” regarding the timeliness and smoothness of the signal. Namely, one cannot achieve a perfectly timely signal (zero phase error in the filter) while at the same time remaining certain that the timely signal estimate is free of unwanted “noise” (perfectly filtered data in the stop-band of the filter). The greater the timeliness (better phase error), the lesser the smoothness (suppression of unwanted high-frequency noise). A happy combination of these two parameters is always desired, and thankfully there exists in iMetrica an interface to optimize these two parameters to achieve a perfect balance given one’s financial trading priorities. There has been much to say on this real-time direct filter “uncertainty” principle, and the interested reader can seek the gory mathematical details in an original paper by the inventor and good friend and colleague Professor Marc Wildi here.
The Secondary Parameters
Regularization of filters is the act of projecting the filter space into a lower dimensional space,reducing the effective number of degrees of freedom. Recently introduced by Wildi in 2012 (see the Elements paper), regularization has three different members to adjust according to the preferences of the signal extraction problem at hand and the data. The regularization parameters are classified as secondary parameters and are found in the Additional Filter Ingredients section in the lower portion of the Real-Time Filter Design interface (Figure 2). The regularization parameters are described as follows.
- Regularization: smoothness. Not to be confused with the smoothness parameter found in the primary list of parameters, this regularization technique serves to project the filter coefficients of the trading signal into an approximation space satisfying a smoothness requirement, namely that the finite differences of the coefficients up to a certain order defined by the smoothness parameter are kept relatively small. This ultimately has the effect that the parameters appear smoother as the smooth parameter increases. Furthermore, as the approximation space becomes more “regularized” according to the requirement that solutions have “smoother” solutions, the effective degrees of freedom decrease and chances of over-fitting will decrease as well. The direct consequences of applying this type of regularization on the signal output are typically quite subtle, and depends clearly on how much smoothness is being applied to the coefficients. Personally, I usually begin with this parameter for my regularization needs to decrease the number of effective degrees of freedom and improve out-of-sample performance.
- Regularization: decay. Employing the decay parameter ensures that the coefficients of the filter decay to zero at a certain rate as the lag of the filter increases. In effect, it is another form of information quantization as the trading signal will tend to lessen the importance of past information as the decay increases. This rate is governed by two decay parameter and higher the value, the faster the values decrease to zero. The first decay parameter adjusts the strength of the decay. The second parameter adjusts for how fast the coefficients decay to zero. Usually, just a slight touch on the strength of the decay and then adjusting for the speed of the decay is the order in which to proceed for these parameters. As with the smoothing regularization, the number of effective degrees of freedom will (in most cases) decreases as the decay parameter decreases, which is a good thing (in most cases).
- Regularization: cross correlation. Used for building trading signals with multivariate data only, this regularization effect groups the latitudinal structure of the multivariate time series more closely, resulting in more weighted estimate of the target filter using the target data frequency information. As the cross regularization parameter increases, the filter coefficients for each time series tend to converge towards each other. It should typically be used in a last effort to control for over-fitting and should only be used if the financial time series data is on the same scale and all highly correlated.
The Tertiary Parameters
- Phase-delay customization. The phase-delay of the filter at frequency zero, defined by the instantaneous rate of change of a filter’s phase at frequency zero, characterizes important information related to the timeliness of the filter. One can directly ensure that the phase delay of the filter at frequency zero is zero by adding constraints to the filter coefficients at computation time. This is done by setting the clicking the
option in the Real-Time Filter Design interface. To go further, one can even set the phase delay to an fixed value other than zero using the
- Differencing weight. This option, found in the Real-Time Filter Design interface as the checkbox labeled “d” (Figure 2), multiplies the frequency information (periodogram or discrete Fourier transform (DFT)) of the financial data by the weighting function
, which is the reciprocal of the differencing operator in the frequency domain. Since the Financial Trading platform in iMetrica strictly uses log-return financial time series to build trading signals, the use of this weighting function is in a sense a frequency-based “de-differencing” of the differenced data. In many cases, using the differencing weight provides better timeliness properties for the filter and thus the trading signal.
In addition to these three levels of parameters used in building real-time trading signals, there is a collection of more exotic “parameterization” strategies that exist in the iMetica MDFA module for fine tuning and constructing boosting trading performance. However, these strategies require more time to develop, a bit of experimentation, and a keen eye for filtering. We will develop more information and tutorials about these advanced filtering techniques for constructing effective trading signals in iMetrica in future articles on this blog coming soon. For now, we just summarize their main ideas.
Advanced Filtering Parameters
- Hybrid filtering. In hybrid filtering, the goal is to filter a target signal additionally by injecting it with another filter of a different type that was constructed using the same data, but different paradigm or set of parameters. One method of hybrid filtering that is readily available in the MDFA module entails constructing Zero-Pole Combination filters using the ZPC Filter Design interface (Figure 4) and injecting the filter into the filter constructed in the Real-Time Filter Design interface (Figure 2) (see Wildi ZPC for more information). The combination (or hybrid) filter can then be accessed using one of the check box buttons in the filter interface and then adjusted using all the various levels of parameters above, and then used in the financial trading interface. The effect of this hybrid construction is to essentially improve either the smoothness or timeliness of any computed trading signal, while at the same time not succumbing to the nasty side-effects of over-fitting.
- Forecasting and Smoothing signals. Smoothing signals in time series, as its name implies, involves obtaining a smoother estimate of certain signal in the past. Since the real-time estimate of a signal value in the past involves using more recent values, the signal estimation becomes more symmetrical as past and future values at a point in the past are used to estimate the value of the signal. For example, if today is after market hours on Friday, we can obtain a better estimate of the targeted signal for Wednesday since we have information from Thursday and Friday. In the opposite manner, forecasting involves projecting a signal into the future. However, since the estimate becomes even more “anti-symmetric”, the estimate becomes more polluted with noise. How these smoothed and forecasted signals can be used for constructing buy/sell trading signals in real-time is still purely experimental. With iMetrica, building and testing strategies that improve trading performance using either smoothed and forecasted signals (or both), is available.To produce either a smoothed or forecasted signal, there is a lag scrollbar available in the Real-Time Filter Design interface under Additional Filter Ingredients that enables one to compute either a smooth or forecasted signal. Setting the lag value
in the scrollbar to any integer between -10 and 10 and the signal with the set lag applied is automatically computed. For negative lag values
- Customized spectral weighting functions. In the spirit of customizing a trading signal to fit one’s priorities in financial trading, one also has the option of customizing the spectral density estimate of the data generating process to any design one wishes. In the computation of the real-time filter, the periodogram (or DFTs in multivariate case) is used as the default estimate of the spectral density weighting function. This spectral density weighting function in theory is supposed to serve as the spectrum of the underlying data generating process (DGP). However, since we have no possible idea about the underlying DGP of the price movement of publicly traded financial assets (other than it’s supposed to be pretty darn close to a random walk according to the Efficient Market Hypothesis), the periodogram is the best thing to an unbiased estimate a mortal human can get and is the default option in the MDFA module of iMetrica. However, customization of this weighting function is certainly possible through the use of the Target Filter Design interface. Not only can one design their target filter for the approximation of the concurrent filter, but the spectral density weighting function of the DGP can also be customized using some of the available options readily available in the interface. We will discuss these features in a soon-to-come discussion and tutorial on advanced real-time filtering methods.
- Adaptive filtering. As perhaps the most advanced feature of the MDFA module, adaptive filtering is an elegant way to achieve building smarter filters based on previous filter realizations. With the goal of adaptive filtering being to improve certain properties of the output signal at each iteration without compensating with over-fitting, the adaptive process is of course highly nonlinear. In short, adaptive MDFA filtering is an iterative process in which a one begins with a desired filter, computes the output signal, and then uses the output signal as explanatory data in the next filtering round. At each iteration step, one has the freedom to change any properties of the filter that they desire, whether it be customization, regularization, adding negative lags, adding filter coefficient constraints, applying a ZPC filter, or even changing the pass-band in the target filter. The hope is to improve on certain properties of filter at each stage of the iterative process. An in-depth look at adaptive filtering and how to easily produce an adaptive filter using iMetrica is soon to come later this week.


 indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.
indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.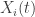 for
for  series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data
series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data 




 -th observation where n is some number much less than the total number of observations $latex N$ in the data set (say, one third the amount). The data sweep then computes the sliding window from
-th observation where n is some number much less than the total number of observations $latex N$ in the data set (say, one third the amount). The data sweep then computes the sliding window from 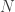 , in increments of one (see Figure 3). At each addition to the length of the window, the forecast is computed for up to 24 steps ahead. Of course, since the true time series data is known in the out-of-sample region of computation, we can compute the forecast error for up to
, in increments of one (see Figure 3). At each addition to the length of the window, the forecast is computed for up to 24 steps ahead. Of course, since the true time series data is known in the out-of-sample region of computation, we can compute the forecast error for up to 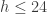 steps ahead and sum up these errors as
steps ahead and sum up these errors as  is the default). Lastly, select how many forecast steps you’d like to use in computing the forecast error (1-24). Once content with the settings, click the “Compute time series sweep” button and watch as the window span increases from
is the default). Lastly, select how many forecast steps you’d like to use in computing the forecast error (1-24). Once content with the settings, click the “Compute time series sweep” button and watch as the window span increases from 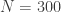 from a SARIMA model of dimension
from a SARIMA model of dimension 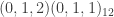 , namely a seasonal auto-regressive integrated moving-average process with two non-seasonal moving-average parameters, and one seasonal moving average parameter. The data sweep is performed on the simulated data with a forecast error horizon of length 23 using three different SARIMA models, (a)
, namely a seasonal auto-regressive integrated moving-average process with two non-seasonal moving-average parameters, and one seasonal moving average parameter. The data sweep is performed on the simulated data with a forecast error horizon of length 23 using three different SARIMA models, (a)  , (b)
, (b) 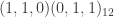 , (c)
, (c) 


