Out-of-sample performance (cash, blue-to-pink line) of an MDFA low-pass filter built using the approach discussed in this article on the STOXX Europe 50 index futures with expiration March 18th (STXEH3) for 200 15-minute interval log-return observations. Only one small loss out-of-sample was recorded from the period of Jan 18th through February 1st, 2013.
Continuing along the trend of my previous installment on strategies and performances of high-frequency trading using multivariate direct filtering, I take on building trading signals for high-frequency index futures, where I will focus on the STOXX Europe 50 Index, S&P 500, and the Australian Stock Exchange Index. As you will discover in this article, these filters that I build using MDFA in iMetrica have yielded some of the best performing trading signals that I have seen using any trading methodology. My strategy as I’ve been developing throughout my previous articles on MDFA has not changed much, except for one detail that I will discuss throughout and will be a major theme of this article, and that relates to an interesting structure found in index futures series for intraday returns. The structure is related to the close-to-open variation in the price, namely when the price at close of market hours significantly differs from the price at open. an effect I’ve mentioned in my previous two articles dealing with high(er)-frequency (or intraday) log-return data. I will show how MDFA can take advantage of this variation in price and profit from each one by ‘predicting’ with the extracted signal the jump or drop in the price at the open of the next trading day.
The frequency of observations on the index that are to be considered for building trading filters using MDFA is typically only a question of taste and priorities. The beauty of MDFA lies in not only the versatility and strength in building trading signals for virtually any financial trading priorities, but also in the independence on the underlying observation frequency of the data. In my previous articles, I’ve considered and built high-performing strategies for daily, hourly, and 15 minute log returns, where the focus of the strategy in building the signal began with viewing the periodogram as the main barometer in searching for optimal frequencies on which one should set the low-pass cutoff for the extracting target filter 
Index futures, as in a futures contract on a financial index, as we will see in this article present no new challenges. With the success I had on the 15-minute return observation frequency that I utilized in my previous article in building a signal for the Japanese Yen, I will continue to use the 15 minute intervals for the index futures where I hope to shed some more light on the filter selection process. This includes deducing properties of the intrinsically optimal spectral peaks to trade on. To do this, I present a simple approach I take in these examples by first setting up a bandpass filter over the spectral peak in the periodogram and then study the in-sample and out-of-sample characteristics of this signal, both in performance and consistency. So without further ado, I present my experiments with financial trading on index futures using MDFA, in iMetrica.
STOXX Europe 50 Index (STXE H3, Expiration March 18 2013)
The STOXX Europe 50 Index, Europe’s leading Blue-chip index, provides a representation of sector leaders in Europe. The index covers 50 stocks from 18 European countries and has the highest trading volume of any European index. One of the first things to notice with the 15-minute log-returns of STXE are the frequent large spikes. These spikes will occur every 27 observations at 13:30 (UTC time zone) due to the fact that there are 26 15-minute periods during the trading hours. These spikes represent the close-to-open jumps that the STOXX Europe 50 index has been subjected to and then reflected in the price of the futures contract. With this ‘seasonal’ pattern so obviously present in the log-return data, the frequency effects of this pattern should be clearly visible in the periodogram of the data. The beauty of MDFA (and iMetrica) is that we have the ability to explicitly engineer a trading signal to take advantage of this ‘seasonal’ pattern by building an appropriate extractor

Figure 1: Log-returns of STXE for the 15-min observations from 1-4-2013 to 2-1-2013
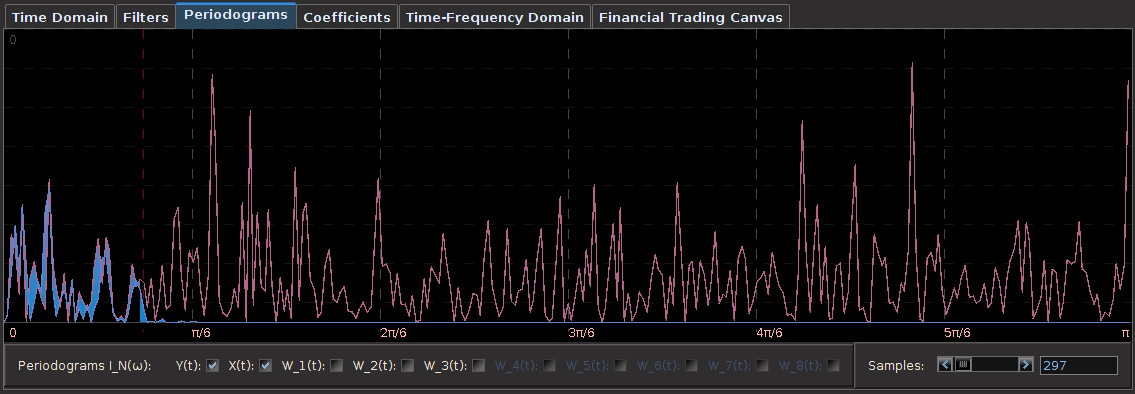
Regarding the periodogram of the data, Figure 2 depicts the periodograms for the 15 minute log-returns of STXE (red) and the explanatory series (pink) together on the same discretized frequency domain. Notice that in both log-return series, there is a principal spectral peak found between .23 and .32. The trick is to localize the spectral peak that accounts for the cyclical pattern that is brought about by the close-to-open variation between 20:00 and 13:30 UTC.

Figure 2: The periodograms for the 15 minute log-returns of STXE (red) and the explanatory series (pink).
In order to see the effects of the MDFA filter when localizing this spectral peak, I use my target 


Figure 3: Choosing the cutoffs for the band pass filter to localize the spectral peak.
Pinpointing this frequency range that zooms in on the largest spectral peak generates a filter that acts on the intrinsic cycles found in the 15 minute log-returns of the STXE futures index. The resulting trading signal produced by this spectral peak extraction is shown in Figure 4, with the returns (blue to pink line) generated from the trading signal (green) , and the price of the STXE futures index in gray. The cyclical effects in the signal include the close-to-open variations in the data. Notice how the signal predicts the variation of the close-to-open price in the index quite well, seen from the large jumps or falls in price every 27 observations. The performance of this simple design in extracting the spectral peak of STXE yields a 4 percent ROI on 200 observations out-of-sample with only 3 losses out of 20 total trades (85 percent trade success rate), with two of them being accounted for towards the very end of the out-of-sample observations in an uncharacteristic volatile period occurring on January 31st 2013.
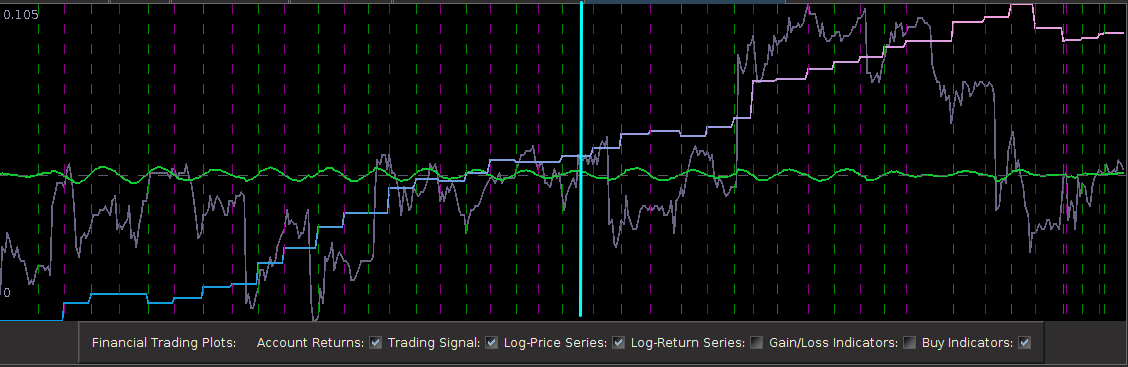
Figure 4: The performance in-sample and out-of-sample of the spectral peak localizing bandpass filter.
The two concurrent frequency response (transfer) functions for the two filters acting on the STXE log-return data (purple) and the explanatory series (blue), respectively, are plotted below in Figure 5. Notice the presence of the spectral peaks for both series being accounted for in the vicinity of the frequency 
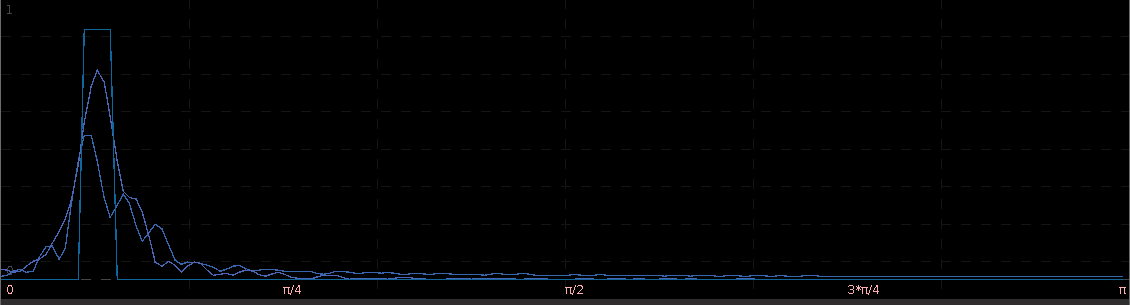
Figure 5: The concurrent frequency response functions of the localizing spectral peak band-pass filter.
With the ideal characteristics of a trading signal quite present in this simple bandpass filter, namely smooth decaying filter coefficients, in-sample and out-of-sample performance properties identical, and accurate, consistent trading patterns, it would be hard to imagine on improving the trading signal for this European futures index even more. But we can. We simply keep the spectral peak frequencies intact, but also account for the local bias in log-return data by extending the lower cutoff to frequency zero. This will provide improved systematic trading characteristics by not only predicting the close-to-open variation and jumps, but also handling upswings and downswings, and highly volatile periods much better.
In this new design, I created a low-pass filter by keeping the upper cutoff 

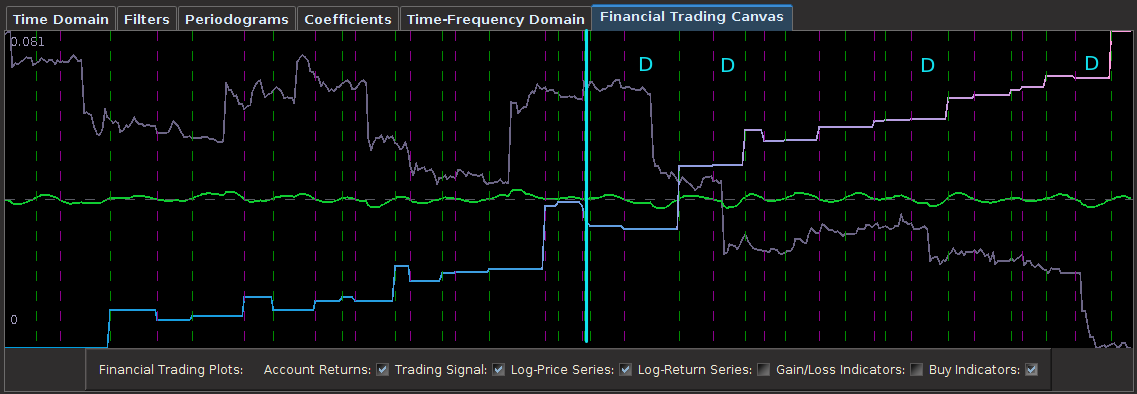
Figure 6: Performance of filter both in-sample (left of cyan line) and on 210 observations out-of-sample (right of cyan line).
Notice that the signal predicted the jump correctly for each of these major jumps, resulting in large returns. For example, at the first “D” indicator, the signal indicated sell/short (magenta dashed line) the STXE future index 5 observations before close, namely at 18:45 UTC, before market close at 20:00 UTC. Sure enough, the price of the STXE contract went down during overnight trading hours and opened far below the previous days close, with the filter signaling a buy (green dashed line) 45 minutes into trading. At the mark of the second “D”, we see that on the final observation before market close, the signal produced a buy/long indication, and indeed, the next day the price of the future jumped significantly.
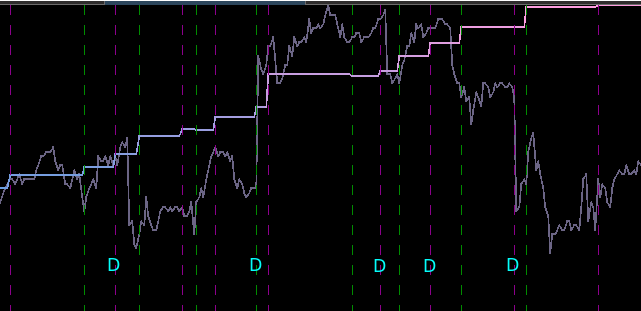
Figure 7: Zooming in on the out-of-sample performance and showing all the signal responses that predicted the major close-to-open jumps.
Only two very small losses of less than .08 percent were accounted for. One advantage of including the frequency zero along with the spectral peak frequency of STXE is that the local bias can help push-up or pull-down the signal resulting in a more ‘patient’ or ‘diligent’ filter that can better handle long upswings/downswings or volatile periods. This is seen in the improvement of the performance towards the end of the 200 observations out-of-sample, where the filter is more patient in signaling a sell/short after the previous buy. Compare this with the end of the performance from the band-pass filter, Figure 4. With this trading signal out-of-sample, I computed a 5 percent ROI on the 200 observations out-of-sample with only 2 small losses. The trading statistics for the entire in-sample combined with out-of-sample are shown in Figure 8.
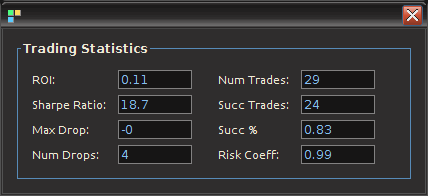
Figure 8: The total performance statistics of the STXEH3 trading signal in-sample plus out-of-sample. The max drop indicates -0 due to the fact that there was a truncation to two decimal places. Thus the losses were less than .01.
S&P 500 Futures Index (ES H3, Expiration March 18 2013)
In this experiment trading S&P 500 future contracts (E-mini) on observations of 15 minute intervals from Jan 4th to Feb 1st 2013, I apply the same regimental approach as before. In looking at the log-returns of ESH3 shown in Figure 10, the effect of close-to-open variation seem to be much less prominent here compared to that on the STXE future index. Because of this, the log-returns seem to be much closer to ‘white noise’ on this index. Let that not perturb our pursuit of a high performing trading signal however. The approach I take for extracting the trading signal, as always, begins with the periodogram.

Figure 10: The log-return data of ES H3 at 15 minute intervals from 1-4-2013 to 2-1-2013.
As the large variations in the close-to-open price are not nearly as prominent, it would make sense that the same spectral peak found before at near
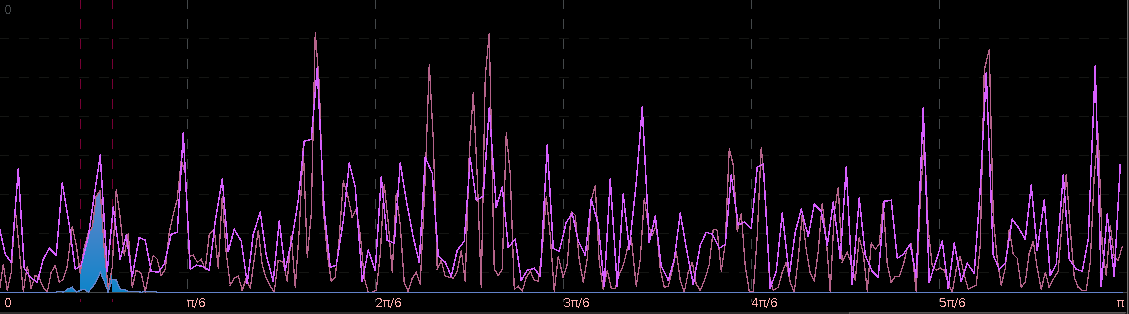
Figure 11: Periodograms of ES H3 log-returns (red) and the explanatory series (pink). The red dashed vertical lines are framing the spectral peak between .23 and .32.
With this spectral peak extracted from the series, the resulting trading signal is shown in Figure 12 with the performance of the bandpass signal shown in Figure 13.

Figure 12: The signal built from the extracted spectral peak and the log-return ESH3 data.
One can clearly see that the trading signal performs very well during the consistent cyclical behavior in the ESH3 price, However, when breakdown occurs in this stochastic structure and follows more prominently another frequency, the trading signal dies and no longer trades systematically taking advantage of the intrinsic cycle found near
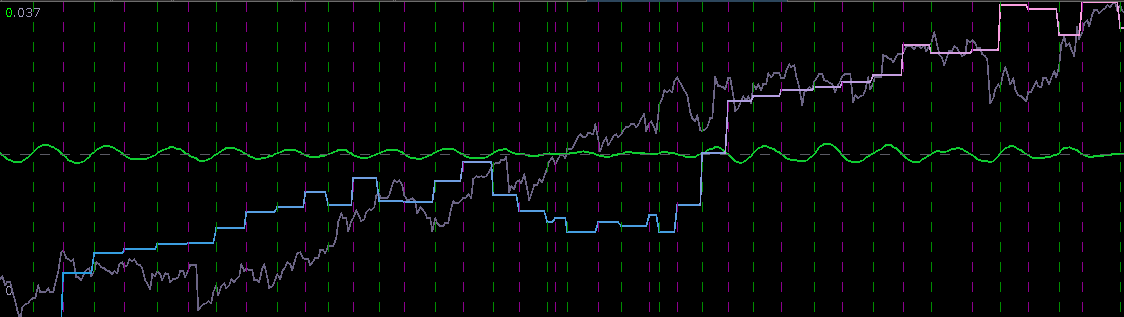
Figure 13: The performance in-sample and out-of-sample of the simple bandpass filter extracting the spectral peak.
Now to improve on these results, we include the frequency zero by moving the lower cutoff of the previous band-pass filter to $\latex \omega_0 = 0$. As I mentioned before, this lifts or pushes down the signal from the local bias and will trade much more systematically. I then lessened the amount of smoothing in the expweight function to 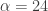
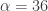

Figure 14: Performance out-of-sample (right of cyan line) of the ES H3 filter on 200 15 minute observations.
The improvement in the overall systematic trading and performance is clear. Most of the major improvements came from the middle 90 points where the trading became less cyclical. With 6 losses in the band-pass design during this period alone, I was able to turn those losses into two large gains and no losses. Only one major loss was accounted for during the 200 observation out-of-sample testing of filter from January 18th to February 1st, with an ROI of nearly 4 percent during the 9 trading days. As with the STXE filter in the previous example, I was able to successfully build a filter that correctly predicts close-to-open variations, despite the added difficulty that such variations were much smaller. Both in-sample and out-of-sample, the filter performs consistently, which is exactly what one strives for thanks to regularization.
ASX Futures (YAPH3, Expiration March 18, 2013)
In the final experiment, I build a trading signal for the Australian Stock Exchange futures, during the same period of the previous two experiments. The log-returns show moderately large jumps/drops in price during the entire sample from Jan 4th to Feb 1st, but not quite as large as in the STXE index. We still should be able to take advantage of these close-to-open variations.

Figure 15: The log-returns of the YAPH3 in 15-minute interval observations.
In looking at the periodograms for both the YAPH3 15 minute log-returns (red) and the explanatory series (pink), it is clear that the spectral peaks don’t align like they did in the previous two exampls. In fact, there hardly exists a dominant spectral peak in the explanatory series, whereas the 

Figure 16: The periodograms for YAPH3 and explanatory series with spectral peak in YAPH3 framed by the red dashed lines.
The performance of the filter in-sample and out-of-sample is shown in Figure 18. This was one of the more challenging index futures series to work with as I struggled finding an appropriate explanatory series (likely because I was lazy since it was late at night and I was getting tired). Nonetheless, the filter still seems to predict the close-to-open variation on the Australian stock exchange index fairly well. All the major jumps in price are accounted for if you look closely at the trades (green dashed lines are buys/long and magenta lines are sells/shorts) and the corresponding action on the price of the futures contract. Five losses out-of-sample for a trade success ratio of 72 percent and an ROI out-of-sample on 200 observations of 4.2 percent. As with all other experiments in building trading signals with MDFA, we check the consistency of the in-sample and out-of-sample performance, and these seem to match up nicely.

Figure 18 : The out-of-sample performance of the low-pass filter on YAPH3.
The filter coefficients for the YAPH3 log-difference series is shown in Figure 19. Notice the perfectly smooth undulating yet decaying structure of the coefficients as the lag increases. What a beauty.
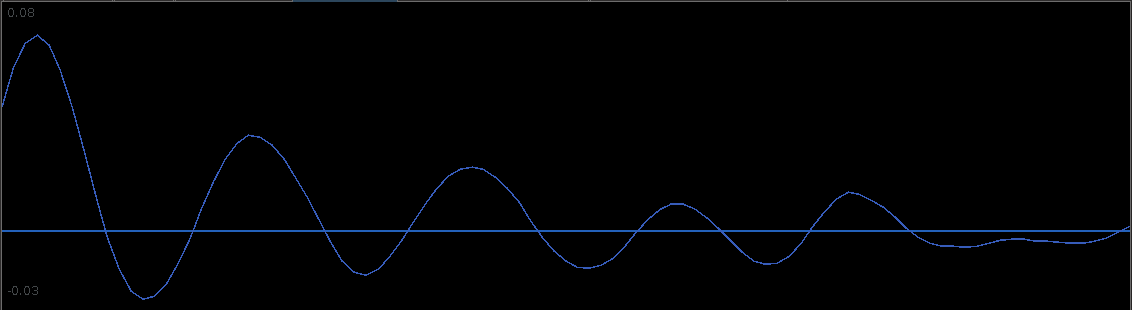
Figure 19: Filter coefficients for the YAPH3 series.
Conclusion
Studying the trading performance of spectral peaks by first constructing band-pass filters to extract the signal corresponding to the peak in these index futures enabled me to understand how I can better construct the lowpass filter to yield even better performance. In these examples, I demonstrated that the close-to-open variation in the index futures price can be seen in the periodogram and thus be controlled for in the MDFA trading signal construction. This trading frequency corresponds to roughly
Stay tuned very soon for a tutorial using R (and MDFA) for one of these examples on high-frequency trading on index futures. If you have any questions or would like to request a certain index future (out of one of the above examples or another) to be dissected in my second and upcoming R tutorial, feel free to shoot me an email.
Happy extracting!

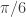 . Notice that both cutoffs are set directly after a spectral peak, something that I highly recommend. In high-frequency trading on the FOREX using MDFA, as we’ll see, the trick is to seek out the spectral peak which accounts for the close-to-open variation in the price of the foreign currency. We want to take advantage of this spectral peak as this is where the big gains in foreign currency trading using MDFA will occur.
. Notice that both cutoffs are set directly after a spectral peak, something that I highly recommend. In high-frequency trading on the FOREX using MDFA, as we’ll see, the trick is to seek out the spectral peak which accounts for the close-to-open variation in the price of the foreign currency. We want to take advantage of this spectral peak as this is where the big gains in foreign currency trading using MDFA will occur.
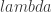 and expweight to 0 along with setting all the regularization parameters to 0 as well. This will give me a barometer for where and how much to adjust the filter parameters. In selecting the filter length
and expweight to 0 along with setting all the regularization parameters to 0 as well. This will give me a barometer for where and how much to adjust the filter parameters. In selecting the filter length 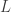 , my empirical studies over numerous experiments in building trading signals using iMetrica have demonstrated that a ‘good’ choice is anywhere between 1/4 and 1/5 of the total in-sample length of the time series data. Of course, the length depends on the frequency of the data observations (i.e. 15 minute, hourly, daily, etc.), but in general you will most likely never need more than
, my empirical studies over numerous experiments in building trading signals using iMetrica have demonstrated that a ‘good’ choice is anywhere between 1/4 and 1/5 of the total in-sample length of the time series data. Of course, the length depends on the frequency of the data observations (i.e. 15 minute, hourly, daily, etc.), but in general you will most likely never need more than  which I’ll stick to for the remainder of this tutorial. In any case, the length of the filter is not the most crucial parameter to consider in building good trading signals. For a good robust selection of the filter parameters couple with appropriate explanatory series, the results of the trading signal with
which I’ll stick to for the remainder of this tutorial. In any case, the length of the filter is not the most crucial parameter to consider in building good trading signals. For a good robust selection of the filter parameters couple with appropriate explanatory series, the results of the trading signal with  compared with, say,
compared with, say,  should hardly differ. If they do, then the parameterization is not robust enough.
should hardly differ. If they do, then the parameterization is not robust enough.






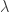 and expweight customization parameters however need to be adjusted to account for the new noise suppression requirements in the stopband and the phase properties in the smaller passband. Thus I increase the smoothing parameter and decreased the timeliness parameter (which only affects the passband) to account for this change. The new frequency response functions and filter coefficients for this smaller lowpass design are shown below in Figure 11. Notice that the second spectral peak is accounted for and only slightly mollified under the new changes. The coefficients still have the noticeable smoothness and decay at the largest lags.
and expweight customization parameters however need to be adjusted to account for the new noise suppression requirements in the stopband and the phase properties in the smaller passband. Thus I increase the smoothing parameter and decreased the timeliness parameter (which only affects the passband) to account for this change. The new frequency response functions and filter coefficients for this smaller lowpass design are shown below in Figure 11. Notice that the second spectral peak is accounted for and only slightly mollified under the new changes. The coefficients still have the noticeable smoothness and decay at the largest lags.



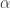 = 13.2,
= 13.2, 




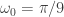
 , but this is typically normal and a non-issue. I had to balance for both timeliness and smoothness in this filter using both the customization parameters
, but this is typically normal and a non-issue. I had to balance for both timeliness and smoothness in this filter using both the customization parameters