In this article we steer away from multivariate direct filtering and signal extraction in financial trading and briefly indulge ourselves a bit in the world of analyzing high-frequency financial data, an always hot topic with the ever increasing availability of tick data in computationally convenient formats. Not only has high-frequency intraday data been the basis of higher frequency risk monitoring and forecasting, but it also provides access to building ‘smarter’ volatility prediction models using so-called realized measures of intraday volatility. These realized measures have been shown in numerous studies over the past 5 years or so to provide a solidly more robust indicator of daily volatility. While daily returns only capture close-to-close volatility, leaving much to be said about the actual volatility of the asset that was witnessed during the day, realized measures of volatility using higher frequency data such as second or minute data provide a much clearer picture of open-to-close variation in trading.
In this article, I briefly describe a new type of volatility model that takes into account these realized measures for volatility movement called High frEquency bAsed VolatilitY (HEAVY) models developed and pioneered by Shephard and Sheppard 2009. These models take as input both close-to-close daily returns 
The goal of this article is three-fold. Firstly, I briefly review these HEAVY models and give some numerical examples of the model in action using a gnu-c library and Java package called heavy_model that I develped last year for the iMetrica software. The heavy_model package is available for download (either by this link or e-mail me) and features many options that are not available in the MATLAB code provided by Sheppard (bootstrapping methods, Bayesian estimation, track reparameterization, among others). I will then demonstrate the seamless ability to model volatility with these High frEquency bAsed VolatilitY models using iMetrica, where I also provide code for computing realized measures of volatility in Java with the help of an R package called highfrequency (Boudt, Cornelissen, and Payseur 2012).
HEAVY Model Definition
Let’s denote the daily returns as 

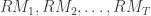



Once the realized measures have been computed for
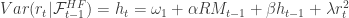

where the stability constraints are ![\alpha, \omega_1 \geq 0, \beta \in [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha%2C+%5Comega_1+%5Cgeq+0%2C+%5Cbeta+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002)

![\lambda + \beta \in [0,1]](https://s0.wp.com/latex.php?latex=%5Clambda+%2B+%5Cbeta+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002)
![\beta_R + \alpha_R \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cbeta_R+%2B+%5Calpha_R+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002)


With the formulation above, one can easily see that slight variations to the model are perfectly plausible. For example, one could consider additional lags in either the realized measure 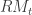

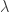


where 
HEAVY modeling in C and Java
To incorporate these HEAVY models into iMetrica, I began by writing a gnu-c library for providing a fast and efficient framework for both quasi-likelihood evaluation and a posteriori analysis of the models. The structure of estimating the models follows very closely to the original MATLAB code provided by Sheppard. However, in the c library I’ve added a few more useful tools for forecasting and distribution analysis. The Java code is essentially a wrapper for the c heavy_model library to provide a much cleaner approach to modeling and analyzing the HEAVY data such as the parameters and forecasts. While there are many ways to declare, implement, and analyze HEAVY models using the c/java toolkit I provide, the most basic steps involved are as follows.
heavyModel heavy = new heavyModel();
heavy.setForecastDimensions(n_forecasts, n_steps);
heavy.setParameterValues(w1, w2, alpha, alpha_R, lambda, beta, beta_R);
heavy.setTrackReparameter(0);
heavy.setData(n_obs, n_series, series);
heavy.estimateHeavyModel();
The first line declares a HEAVY model in java, while the second line sets the number of forecasts samples to compute and how many forecast steps to take. Forecasted values are provided for both the return variable 

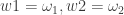
The fourth line is completely optional and is used for toggling (0=off, 1=on) a reparameterization of the HEAVY model so the intercepts of both equations in the HEAVY model are explicitly related to the unconditional mean of squared returns 

heavy.printModelParameters();
heavy.plotForecasts();
Output:
w_1 = 0.063 w_2 = 0.053
beta = 0.855 beta_R = 0.566
alpha = 0.024 alpha_R = 0.375
lambda = 0.087
Figure 1 shows the plot of the filtered 

Figure 1: Plots of the filtered returns and realized measures with 20 step forecasts for Verizon for 300 trading days.
We can also easily plot the estimated joint distribution function 

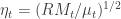

Figure 2 below shows the empirical distribution of

Figure 2: Scatter plot of the empirical distribution of devolatilized values for h and mu.
In order to compile and run the heavy_model library and the accompanying java wrapper, one must first be sure to meet the requirements for installation. The programs were extensively tested on a 64bit Linux machine running Ubuntu 12.04. The heavy_model library written in c uses the GNU Scientific Library (GSL) for the matrix-vector routines along with a statistical package in gnu-c called apophenia (Klemens, 2012) for the optimization routine. I’ve also included a wrapper for the GSL library called multimin.c which enables using the optimization routines from the GSL library, but were not heavily tested. The first version (version 00) of the heavy_model library and java wrapper can be downloaded at sourceforge.net/projects/highfrequency. As a precautionary warning, I must confess that none of the files are heavily commented in any way as this is still a project in progress. Improvements in code, efficiency, and documentation will be continuously coming.
After downloading the .tar.gz package, first ensure that GSL and Apophenia are properly installed and the libraries are correctly installed to the appropriate path for your gnu c compiler. Second, to compile the .c code, copy the makefile.test file to Makefile and then type make. To compile the heavyModel library and utilize the java heavyModel wrapper (recommended), copy makefile.lib to Makefile, then type make. After it constructs the libheavy.so, compile the heavyModel.java file by typing javac heavyModel.java. Note that the java files were complied successfully using the Oracle Java 7 SDK. If you have any questions about this or any of the c or java files, feel free to contact me. All the files were written by me (except for the optional multimin.c/h files for the optimization) and some of the subroutines (such as the HEAVY model simulation) are based on the MATLAB code by Sheppard. Even though I fully tested and reproduced the results found in other experiments exploring HEAVY models, there still could be bugs in the code. I have not fully tested every aspect (especially the Bayesian estimation components, an ongoing effort) and if anyone would like to add, edit, test, or comment on any of the routines involved in either the c or java code, I’d be more than happy to welcome it.
HEAVY Modeling in iMetrica
The Java wrapper to the gnu-c heavy_model library was installed in the iMetrica software package and can be used for GUI style modeling of high-frequency volatility. The HEAVY modeling environment is a feature of the BayesCronos module in iMetrica that also features other stochastic models for capturing and forecasting volatility such as (E)GARCH, stochastic volatility, mutlivariate stohastic factor modeling, and ARIMA modeling, all using either standard (Q)MLE model estimation or a Bayesian estimation interface (with histograms showing the MCMC results of the parameter chains).
Modeling volatility with HEAVY models is done by first uploading the data into the BayesCronos module (shown in Figure 3) through the use of either the BayesCronos Menu (featured on the top panel) or by using the Data Control Panel (see my previous article on Data Control).

Figure 3: BayesCronos interface in iMetrica for HEAVY modeling.
In the BayesCronos control panel shown above, we estimate a HEAVY model for the uploaded data (600 observations of 
The model type is selected in the panel under the Model combobox. The number of forecasting steps and forecasting samples (for the
Realized Measures in iMetrica
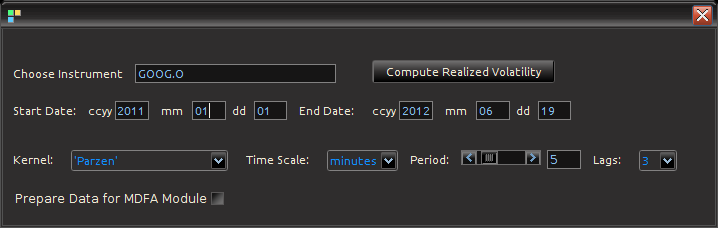
Figure 4: Computing Realized measures in iMetrica using a convenient realized measure control panel.
Importing and computing realized volatility measures in iMetrica is accomplished by using the control panel shown in Figure 4. With access to high frequency data, one simply types in the ticker symbol in the “Choose Instrument” box, sets the starting and ending date in the standard CCYY-MM-DD format, and then selects the kernel used for assembling the intraday measurements. The Time Scale sets the frequency of the data (seconds, minutes hours) and the period scrollbar sets the alignment of the data. The Lags combo box determines the bandwidth of the kernel measuring the volatility. Once all the options have been set, clicking on the “Compute Realized Volatility” button will then produce three data sets for the time period given between start date and end data: 1) The daily log-returns of the asset 


Figure 5: The log-return data (blue) and the (annualized) realized measure data using 5 minute returns (pink) for Google from 1-1-2011 to 6-19-2012.
The Realized Measure uploading in iMetrica utilizes a fantastic R package for studying and working with high frequency financial data called highfrequency (Boudt, Cornelissen, and Payseur 2012). To handle the analysis of high frequency financial data in java, I began by writing a Java wrapper to the R functions of the highfrequency R package to enable GUI interaction shown above in order to download the data into java and then iMetrica. The java environment uses library called RCaller that opens a live R kernel in the Java runtime environment from which I can call and R routines and directly load the data into Java. The initializing sequence looks like this.
caller.getRCode().addRCode("require (Runiversal)");
caller.getRCode().addRCode("require (FinancialInstrument)");
caller.getRCode().addRCode("require (highfrequency)");
caller.getRCode().addRCode("loadInstruments('/HighFreqDataDirectoryHere/Market/instruments.rda')");
caller.getRCode().addRCode("setSymbolLookup.FI('/HighFreqDataDirectoryHere/Market/sec',use_identifier='X.RIC',extension='RData')");
Here, I’m declaring the R packages that I will be using (first three lines) and then I declare where my HighFrequency financial data symbol lookup directory is on my computer (next two lines). This
then enables me to extract high frequency tick data directly into Java. After loading in the desired intrument ticker symbol names, I then proceed to extract the daily log-returns for the given time frame, and then compute the realized measures of each asset using the rKernelCov function in highfrequency R package. This looks something like
for(i=0;i<n_assets;i++)
{
String mark = instrum[i] + "<-" + instrum[i] + "['T09:30/T16:00',]";
caller.getRCode().addRCode(mark);
String rv = "rv"+i+"<-rKernelCov("+instrum[i]+"$Trade.Price,kernel.type ="+kernels[kern]+", kernel.param="+lags+",kernel.dofadj = FALSE, align.by ="+frequency[freq]+", align.period="+period+", cts=TRUE, makeReturns=TRUE)"
caller.getRCode().addRCode(rv);
caller.getRCode().addRCode("names(rv"+i+")<-'rv"+i+"'");
rvs[i] = "rv_list"+i;
caller.getRCode().addRCode("rv_list"+i+"<-lapply(as.list(rv"+i+"), coredata)");
}
In the first line, I’m looping through all the asset symbols (I create Java strings to load into the RCaller as commands). The second line effectively retrieves the data during market hours only (America/New_York time), then creates a string to call the rKernelCov function in R. I give it all the user defined parameters defined by strings as well. Finally, in the last two lines, I extract the results and put them into an R list from which the java runtime environment will read.
Conclusion
In this article I discussed a recently introduced high frequency based volatility model by Shephard and Sheppard and gave an introduction to three different high-performance tools beyond MATLAB and R that I’ve developed for analyzing these new stochastic models. The heavyModel c/java package that I made available for download gives a workable start for experimenting in a fast and efficient framework the benefit of using high frequency financial data and most notably realized measures of volatility to produce better forecasts. The package will continuously be updated for improvements in both documentation, bug fixes, and overall presentation. Finally, the use of the R package highfrequency embedded in java and then utilized in iMetrica gives a fully GUI experience to stochastic modeling of high frequency financial data that is both conveniently easy to use and fast.
Happy Extracting and Volatilitizing!


 indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.
indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.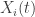 for
for  series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data
series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data 




 -th observation where n is some number much less than the total number of observations $latex N$ in the data set (say, one third the amount). The data sweep then computes the sliding window from
-th observation where n is some number much less than the total number of observations $latex N$ in the data set (say, one third the amount). The data sweep then computes the sliding window from 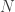 , in increments of one (see Figure 3). At each addition to the length of the window, the forecast is computed for up to 24 steps ahead. Of course, since the true time series data is known in the out-of-sample region of computation, we can compute the forecast error for up to
, in increments of one (see Figure 3). At each addition to the length of the window, the forecast is computed for up to 24 steps ahead. Of course, since the true time series data is known in the out-of-sample region of computation, we can compute the forecast error for up to 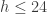 steps ahead and sum up these errors as
steps ahead and sum up these errors as  is the default). Lastly, select how many forecast steps you’d like to use in computing the forecast error (1-24). Once content with the settings, click the “Compute time series sweep” button and watch as the window span increases from
is the default). Lastly, select how many forecast steps you’d like to use in computing the forecast error (1-24). Once content with the settings, click the “Compute time series sweep” button and watch as the window span increases from 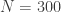 from a SARIMA model of dimension
from a SARIMA model of dimension 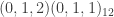 , namely a seasonal auto-regressive integrated moving-average process with two non-seasonal moving-average parameters, and one seasonal moving average parameter. The data sweep is performed on the simulated data with a forecast error horizon of length 23 using three different SARIMA models, (a)
, namely a seasonal auto-regressive integrated moving-average process with two non-seasonal moving-average parameters, and one seasonal moving average parameter. The data sweep is performed on the simulated data with a forecast error horizon of length 23 using three different SARIMA models, (a)  , (b)
, (b) 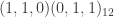 , (c)
, (c) 



