
Animation 1: Click the image to view the animation. The changing periodogram for different in-sample sizes and selecting an appropriate band-pass component to the multi-bandpass filter.
In my previous article, the third installment of the Frequency Effect trilogy, I introduced the multi-bandpass (MBP) filter design as a practical device for the extraction of signals in financial data that can be used for trading in multiple types of market environments. As depicted through various examples using daily log-returns of Google (GOOG) as my trading platform, the MBP demonstrated a promising ability to tackle the issue of combining both lowpass filters to include a local bias and slow moving trend while at the same time providing access to higher trading frequencies for systematic trading during sideways and volatile market trajectories. I identified four different types of market environments and showed through three different examples how one can attempt to pinpoint and trade optimally in these different environments.
After reading a well-written and informative critique of my latest article, I became motivated to continue along on the MBP bandwagon by extending the exploration of engineering robust trading signals using the new design. In Marc’s words (the reviewer) regarding the initial results of this latest design in MDFA signal extraction for financial trading : “I tend to believe that some of the results are not necessarily systematic and that some of the results – Chris’ preference – does not match my own priority. I understand that comparisons across various designs of the triptic may require a fixed empirical framework (Google/Apple on a fixed time span). But this restricted setting does not allow for more general inference (on other assets and time spans). And some of the critical trades are (at least in my perspective) close to luck.”
As my empirical framework was fixed in that I applied the designed filters to only one asset throughout the study and for a fixed time span of a year worth of in-sample data applied to 90 days out-of-sample, results showing the MBP framework applied to other assets and time frames might have made my presentation of this new design more convincing. Taking this relevant issue of limited empirical framework into account, I am extending my previous article many steps further by presenting in this article the creation of a collection of financial trading signals based entirely on the MBP filter. The purpose of this article is to further solidify the potential for MBP filters and extend applications of the new design to constructing signals for various types of financial assets and in-sample/out-of-sample time frames. To do this I will create a portfolio of assets comprised of a group of well known companies coupled with two commodity ETFs (exchange traded funds) and apply the MBP filter strategy to each of the assets using various out-of-sample time horizons. Consequently, this will generate a portfolio of trading signals that I can track over the next several months.
Portfolio selection
In choosing the assets for my portfolio, I arranged a group of companies/commodities whose products or services I use on a consistent basis (as arbitrary as any other portfolio selection method, right?). To this end, I chose Verizon (VZ) (service provider for my iPhone5), Microsoft (MSFT) (even though I mostly use Linux for my computing needs), Toyota (TM) ( I drive a Camry), Coffee (JO) (my morning espresso keeps the wheels turning), and Gold (GLD) (who doesn’t like Gold, a great hedge to any currency). For each of these assets, I built a trading signal using various in-sample time periods beginning summer of 2011 and ending toward the end of summer 2012, to ensure all seasonal market effects were included. The out-of-sample time period in which I test the performance of the filter for each asset ranges anywhere from 90 days to 125 days out-of-sample. I tried to keep the selection of in-sample and out-of-sample points as arbitrary as possible.
Portfolio Performance
And so here we go. The performance of the portfolio.
Coffee (NYSEARCA:JO)
- Regularization: smooth = .22, decay = .22, decay2 = .02, cross = 0
- MBP = [0, .2], [.44,.55]
- Out-of-sample performance: 32 percent ROI in 110 days
In order to work with commodities in this portfolio, the easiest way is through the use of ETFs that are traded in open markets just as any other asset. I chose the Dow Jones-UBS Coffee Subindex JO which is intended to reflect the returns that are potentially available through an unleveraged investment in one futures contract on the commodity of coffee as well as the rate of interest that could be earned on cash collateral invested in specified Treasury Bills. To create the MBP filter for the JO index, I used JO and USO (a US Oil ETF) as the explanatory series from the dates of 5-5-2011 until 1-13-2013 (just a random date I picked from mid 2011, cinqo de mayo) and set the initial low-pass portion for the trend component of the MBP filter to [0, .17]. After a significant amount of regularization was applied, I added a bandpass portion to the filter by initializing an interval at [.4, .5]. This corresponded to the principal spectral peak in the periodogram which was located just below 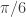

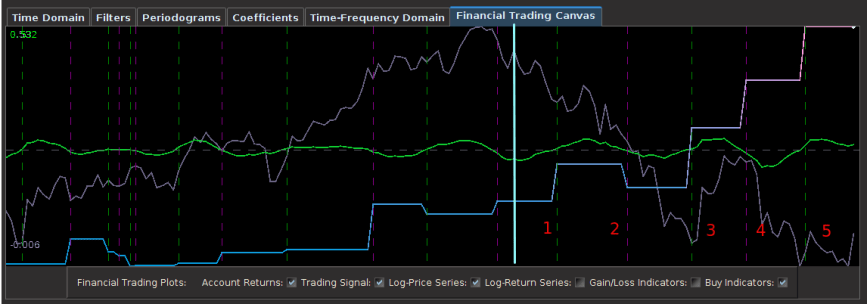
Figure 1: The MBP filter for JO applied 110 Out-of-sample points (after cyan line).

Figure 2: Transfer function for the JO and USO MBP filters.
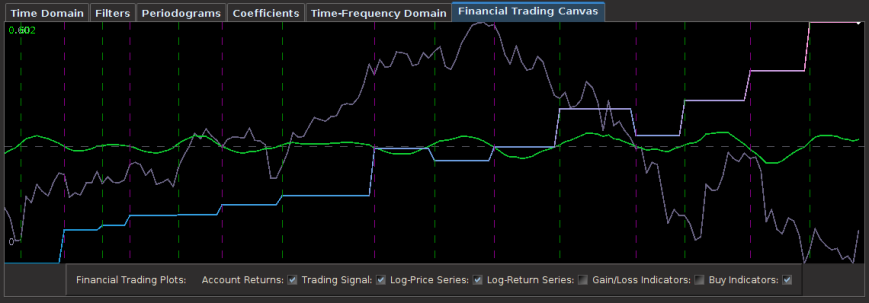
Notice the out-of-sample portion of 110 observations behaving akin to the in-sample portion before it, with a .97 rank coefficient of the cumulative ROI resulting from the trades. The ROI in the out-of-sample portion was 32 percent total and suffered only 4 small losses out of 18 trades. The concurrent transfer functions of the MBP filter clearly indicate where the principal spectral peak for JO (blue-ish line) is directly under the bandpass portion of the filter. Notice the signal produced no trades during the steepest descent and rise in the price of coffee, while pinpointing precisely at the right moment the major turning point (right after the in-sample period). This is exactly what you would like the MBP signal to achieve.
Gold (SPDR Gold Trust, NYSEARCA:GLD)
As one of the more difficult assets to form a well-performing signal both in-sample and out-of-sample using the MBP filter, the GLD (NYSEARCA:GLD) ETF proved to be quite cumbersome in not only locating an optimal bandpass portion to the MBP, but also finding a relevant explaining series for GLD. In the following formulation, I settled upon using a US dollar index given by the PowerShares ETF UUP (NYSEARCA:UUP), as it ended up giving me a very linear performance that is consistent both in-sample and out-of-sample. The parameterization for this filter is given as follows:
- Regularization: smooth = .22, decay = .22, decay2 = .02, cross = 0
- MBP = [0, .2], [.44,.55]
- Out-of-sample performance: 11 percent ROI in 102 days

Figure 3 : Out-of-sample results of the MBP applied to the GLD ETF for 102 observations

Figure 4 : The Transfer Functions for the GLD and DIG filter.

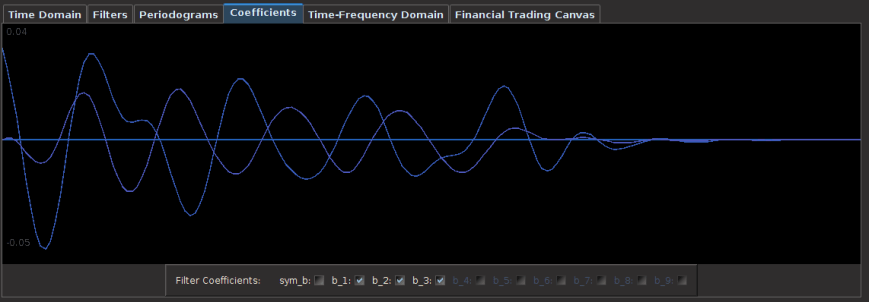
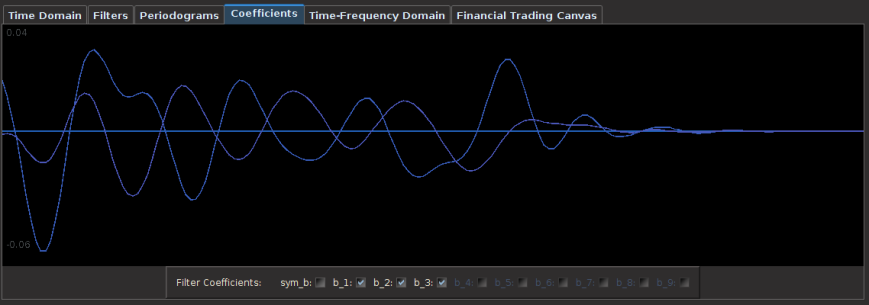
Figure 5: Coefficients for the GLD and DIG filters. Each are of length 76.
The smoothness and decay in the coefficients is quite noticeable along with a slight lag correlation along the middle of the coefficients between lags 10 and 38. This trio of characteristics in the above three plots is exactly what one strives for in building financial trading signals. 1) The smoothness and decay of the coefficients, 2) the transfer functions of the filter not exceeding 1 in the low and band pass, and 3) linear performance both in-sample and out-of-sample of the trading signal.
Verizon (NYSE:VZ)
- Regularization: smooth = .22, decay = 0, decay2 = 0, cross = .24
- MBP = [0, .17], [.58,.68]
- Out-of-sample performance: 44 percent ROI in 124 days trading
The experience of engineering a trading signal for Verizon was one of the longest and more difficult experiences out of the 5 assets in this portfolio. Strangely a very difficult asset to work with. Nevertheless, I was determined to find something that worked. To begin, I ended up using AAPL as my explanatory series (which isn’t a far fetched idea I would imagine. After all, I utilize Verizon as my carrier service for my iPhone 5). After playing around with the regularization parameters in-sample, I chose a 124 day out-of-day horizon for my Verizon to apply the filter to and test the performance. Surprisingly, the cross regularization seemed to produce very good results both out-of-sample. This was the only asset in the portfolio that required a significant amount of cross regularization, with the parameter touching the vicinity of .24. Another surprise was how high the timeliness parameter 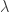
The out-of-sample performance is shown in Figure 6. Notice how dampened the values of the trading signal are in this example, where the local bias during the long upswings is present, but not visible due to the size of the plot. The out-of-sample performance (after the cyan line) seems to be superior to that of the in-sample portion. This is most likely due to the fact that the majority of the frequencies that we were interested in, near

Figure 6: The out-of-sample performance on 124 observations from 7-2012 to 1-13-2013.

Figure 7: Coefficients of lag up to 76 of the Verizon-Apple filter,
In the coefficients for the VZ and AAPL data shown in Figure 7, one can clearly see the distinguishing effects of the cross regularization along with the smooth regularization. Note that no decay regularization was needed in this example, with the resulting number of effective degrees of freedom in the construction of this filter being 48.2 an important number to consider when applying regularization to filter coefficients (filter length was 76),
Microsoft (NASDAQ:MSFT)
- Regularization: smooth = .42, decay = .24, decay2 = .15, cross = 0
- MBP = [0, .2], [.59,.72]
- Out-of-sample performance: 31 percent ROI in 90 days trading
In the Microsoft data I used a time span of a year and three months for my in-sample period and a 90 day out-of-sample period from August through 1-13-2012. My explanatory series was GOOG (the search engine Bing and Google seem to have quite the competition going on, so why not) which seemed to correlate rather cleanly with the share price of MSFT. The first step in obtaining a bandpass after setting my lowpass filter to [0, .2] was to locate the principal spectral peak (shown in the periodogram figure below). I then adjusted the width until I had near monotone performance in-sample. Once the customization and regularization parameters were found, I applied the MSFT/AAPL filter to the 90 day out-of-sample period and the result is shown below. Notice that the effect of the local bias and slow moving trends from the lowpass filter are seen in the output trading signal (green) and help in identifying the long down swings found in the share price. During the long down swings, there are no trades due to the local bias from frequency zero.

Figure 8: Microsoft trading signal for 90 out-of-sample observations. The ROI out-of-sample is 31 percent.

Figure 9: Aggregate periodogram of MSFT and Google showing the principal spectral peak directly inside the bandpass.

Figure 10: The coefficients for the MSFT and GOOG series up to lag 76.
With a healthy amount of regularization applied to the coefficient space, we can clearly see the smoothness and decay towards the end of the coefficient lags. The cross regularization parameter provided no improvement to either in-sample or out-of-sample performance and was left set to 0.
Despite the superb performance of the signal out-of-sample with a 31 percent ROI in 90 days in a period which saw the share price descend by 10 percent, and relatively smooth decaying coefficients with consistent performance both in and out-of-sample, I still feel like I could improve on these results with a better explanatory series than AAPL. That is one area of this methodology in which I struggle, namely finding “good” explanatory series to better fortify the in-sample metric space and produce more even more anticipation in the signals. At this point it’s a game of trial and error. I suppose I should find a good market economist to direct these questions to.
Toyota (NYSE:TM)
- Regularization: smooth = .90, decay = .14, decay2 = .72, cross = 0
- MBP = [0, .21], [.49,.67]
- Out-of-sample performance: 21 percent ROI in 85 days trading
For the Toyota series, I figured my first explanatory series to test things with would be an asset pertaining to the price of oil. So I decided to dig up some research and found that DIG ( NYSEARCA:DIG), a ProShares ETF, provides direct exposure to the global price of oil and gas (in fact it is leveraged so it corresponds to twice the daily performance of the Dow Jones U.S. Oil & Gas Index). The out-of-sample performance, with heavy regularization in both smooth and decay, seems to perform quite consistently with in-sample, The signal shows signs of patience during volatile upswings, which is a sign that the local bias and slow moving trend extraction is quietly at work. Otherwise, the gains are consistent with just a few very small losses. At the end of the out-of-sample portion, namely the past several weeks since Black Friday (November 23rd), notice the quick climb in stock price of Toyota. The signal is easily able to deduce this fast climb and is now showing signs of slowdown from the recent rise (the signal is approaching the zero crossing, that’s how I know). I love what you do for me, Toyota! (If you were living in the US in the1990s, you’ll understand what I’m referring to).

Figure 11: Out-of-sample performance of the Toyota trading signal on 85 trading days.
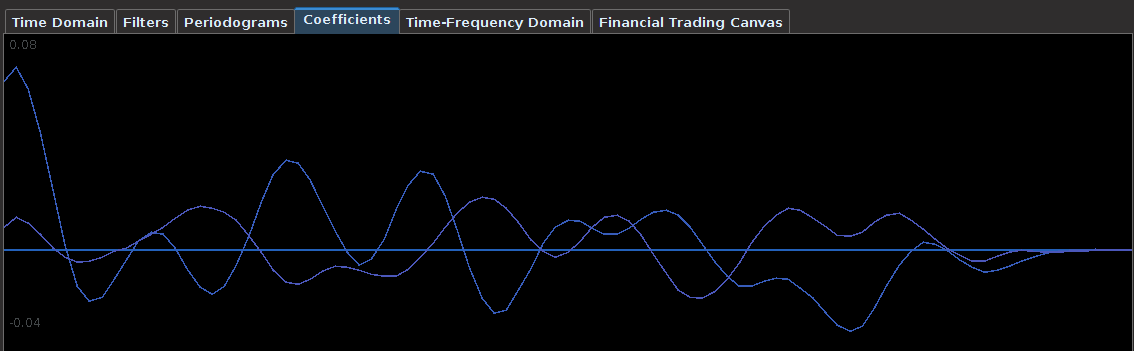
Figure 12: Coefficients for the TM and DIG log-return series.
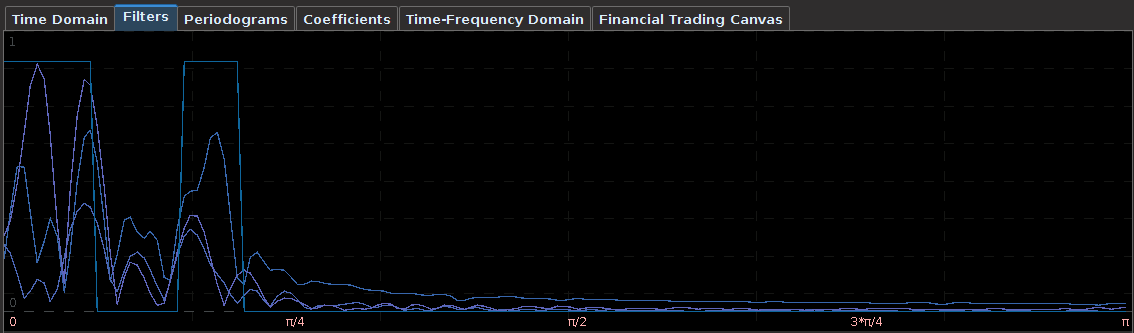
Figure 13: The transfer functions for the TM and DIG filter coefficients.
The coefficients for the TM and DIG series depicted in Figure 12 show the heavy amount of smooth and decay (and decay2) regularization, a trio of parameters that was not easy to pinpoint at first without significant leakage above one in the filter transfer functions (shown in Figure 13). One can see that two major spectral peaks are present under the lowpass portion and another large one in the bandpass portion that accounts for the more frequent trades.
Conclusion
With these trading signals constructed for these five assets, I imagine I have a small but somewhat diverse portfolio, ranging from tech and auto to two popular commodities. I’ll be tracking the performance of these trading signals together combined as a portfolio over the next few months and continuously give updates. As the in-sample periods for the construction of these filters ended around the end of last summer and were already applied to out-of-sample periods ranging from 90 days to 124 (roughly one half to one third of the original in-sample period), with the significant amount of regularization applied, I am quite optimistic that the out-of-sample performance will continue to be the same over the next few months, but of course one can never be too sure of anything when it comes to market behavior. In the worse case scenario, I can always look into digging though my dynamic adaptive filtering and signal extraction toolkit.
Some general comments as I conclude this article. What I truly enjoy about these trading signals constructed for this portfolio experiment (and robust trading signals in general per my other articles on financial trading) is that when any losses out-of-sample or even in-sample occur, they tend to be extremely small relative to the average size of the gains. That is the sign of a truly robust signal I suppose; that not only does it perform consistently both in-sample and out-of-sample, but also that when losses do arrive, they are quite small. One characteristic that I noticed in all robust and high performing trading signals that I tend to stick with is that no matter what type of extraction definition you are targeting (lowpass, bandpass, or MBP), when an erroneous trade is executed (leading to a loss), the signal will quickly correct itself to minimize the loss. This is why the losses in robust signals tend to be small (look at any of the 5 trading signals produced for the portfolio in this article). Of course, all these good trading signal characteristics are in addition to the filter characteristics (smooth, slightly decaying coefficients with minimal effective degrees of freedom, transfer functions less than or equal to one everywhere, etc.)
Overall, although I’m quite inspired and optimistic with these results. there is still slight room for improvement in building these MBP filters, especially for low volatility sideways markets (for example, the one occurring in the Toyota stock price in the middle of the plot in Figure 11). In general, this is a difficult type of stock price movement in which any type of signal will have success. With low volatility and no trending movements, the log-returns are basically white noise – there is no pertinent information to extract. The markets are currently efficient and there is nothing you can do about it. Only good luck will win (in that case you’re as well off building a signal based on a coin flip). Typically the best you can do in these types of areas is prevent trading altogether with some sort of threshold on the signal, which is an idea I’ve had in my mind recently but haven’t implemented, or make sure any losses are small, which is exactly what my signal achieved in Figure 11 (and which is what any robust signal should do in the first place.)
Lastly, if you have a particular financial asset for which you would like to build a trading signal (similar to the examples shown above), I will be happy to take a stab at it using iMetrica (and/or give you pointers in the right direction if you would prefer to pursue the endeavor yourself). Just send me what asset you would like to trade on, and I’ll build the filter and send you the coefficients along with the parameters used. Offer holds for a limited time only!
Happy extracting.

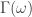 (see my previous two articles on The Frequency Effect). Designating a lowpass or bandpass filter in the frequency domain will give an indication of what kind of patterns the extracted trading signal will trade on. Traditionally one can set a lowpass with the goal of extracting trends (with the proper amount of timeliness prioritized in the parameterization), or one can opt for a bandpass to extract smaller cyclical events for more systematic trading during volatile periods. But now suppose we could have the best of both worlds at the same time. Namely, be profitable in both steady climbs and long tumbles, while at the same time systematically hacking our way through rough sideways volatile territory, making trades at specific frequencies embedded in the share price actions not found in long trends. The answer is through the construction of multi-band pass filters. Their construction is relatively simple, but as I will demonstrate in this article with many examples, they are a bit more difficult to pinpoint optimally (but it can be done, and the results are beautiful… both aesthetically and financially).
(see my previous two articles on The Frequency Effect). Designating a lowpass or bandpass filter in the frequency domain will give an indication of what kind of patterns the extracted trading signal will trade on. Traditionally one can set a lowpass with the goal of extracting trends (with the proper amount of timeliness prioritized in the parameterization), or one can opt for a bandpass to extract smaller cyclical events for more systematic trading during volatile periods. But now suppose we could have the best of both worlds at the same time. Namely, be profitable in both steady climbs and long tumbles, while at the same time systematically hacking our way through rough sideways volatile territory, making trades at specific frequencies embedded in the share price actions not found in long trends. The answer is through the construction of multi-band pass filters. Their construction is relatively simple, but as I will demonstrate in this article with many examples, they are a bit more difficult to pinpoint optimally (but it can be done, and the results are beautiful… both aesthetically and financially).![A := 1_{[\omega_0, \omega_1]}](https://s0.wp.com/latex.php?latex=A+%3A%3D+1_%7B%5B%5Comega_0%2C+%5Comega_1%5D%7D&bg=ffffff&fg=323232&s=0&c=20201002) ,
, ![B := 1_{[\omega_2, \omega_3]}](https://s0.wp.com/latex.php?latex=B+%3A%3D+1_%7B%5B%5Comega_2%2C+%5Comega_3%5D%7D&bg=ffffff&fg=323232&s=0&c=20201002) with
with  and
and  , zero everywhere else, it is easy to see that the motivation here is to seek a detection of both lower frequencies and low-mid frequencies in the data concurrently. With now up to four cutoff frequencies to choose from, this adds yet another few wrinkles in the degrees of freedom in parameterizing the MDFA setup. If choosing and optimizing one cutoff frequency for a simple low-pass filter in addition to customization and regularization parameters wasn’t enough, now imagine extracting signals with the addition of up to three more cutoff frequencies. Despite these additional degrees of freedom in frequency interval selection, I will later give a couple of useful hacks that I’ve found helpful to get one started down the right path toward successful extraction.
, zero everywhere else, it is easy to see that the motivation here is to seek a detection of both lower frequencies and low-mid frequencies in the data concurrently. With now up to four cutoff frequencies to choose from, this adds yet another few wrinkles in the degrees of freedom in parameterizing the MDFA setup. If choosing and optimizing one cutoff frequency for a simple low-pass filter in addition to customization and regularization parameters wasn’t enough, now imagine extracting signals with the addition of up to three more cutoff frequencies. Despite these additional degrees of freedom in frequency interval selection, I will later give a couple of useful hacks that I’ve found helpful to get one started down the right path toward successful extraction. comes the responsibility to ensure that the customization of smoothness and timeliness is adjusted for the additional passband. The smoothing function
comes the responsibility to ensure that the customization of smoothness and timeliness is adjusted for the additional passband. The smoothing function 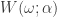 for
for 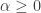 that acts on the periodogram (or discrete Fourier transforms in multivariate mode) is now defined piecewise according to the different intervals
that acts on the periodogram (or discrete Fourier transforms in multivariate mode) is now defined piecewise according to the different intervals ![[0,\omega_0]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Comega_0%5D&bg=ffffff&fg=323232&s=0&c=20201002) ,
, ![[\omega_1, \omega_2]](https://s0.wp.com/latex.php?latex=%5B%5Comega_1%2C+%5Comega_2%5D&bg=ffffff&fg=323232&s=0&c=20201002) , and
, and ![[\omega_3, \pi]](https://s0.wp.com/latex.php?latex=%5B%5Comega_3%2C+%5Cpi%5D&bg=ffffff&fg=323232&s=0&c=20201002) . For example,
. For example,  gives a piecewise quadratic weighting function (an example shown in Figure 1) and for
gives a piecewise quadratic weighting function (an example shown in Figure 1) and for 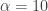 , the weighting function is piecewise linear. In practice, the piecewise power function smooths and rids of unwanted frequencies in the stop band much better than using a piecewise constant function. With these preliminaries defined, we now move on to the first steps in building and applying multiband pass filters.
, the weighting function is piecewise linear. In practice, the piecewise power function smooths and rids of unwanted frequencies in the stop band much better than using a piecewise constant function. With these preliminaries defined, we now move on to the first steps in building and applying multiband pass filters.
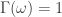 if
if ![\omega \in [0,.17]](https://s0.wp.com/latex.php?latex=%5Comega+%5Cin+%5B0%2C.17%5D&bg=ffffff&fg=323232&s=0&c=20201002) , and 0 otherwise. This formulation, as it includes the zero frequency, should provide a local bias as well as extract very slow moving trends. The trick with these filters for building consistent trading performance is ensure a proper grip on the timeliness characteristics of the filter in a very low and narrow filter passage. Regularization and smoothness using the weighting function shouldn’t be too much of a problem or priority as typically just only a small fraction of the available degrees of freedom on the frequency domain are being utilized, so not much concern for overfitting as long as you’re not using too long of a filter. In my example, I maxed out the timeliness
, and 0 otherwise. This formulation, as it includes the zero frequency, should provide a local bias as well as extract very slow moving trends. The trick with these filters for building consistent trading performance is ensure a proper grip on the timeliness characteristics of the filter in a very low and narrow filter passage. Regularization and smoothness using the weighting function shouldn’t be too much of a problem or priority as typically just only a small fraction of the available degrees of freedom on the frequency domain are being utilized, so not much concern for overfitting as long as you’re not using too long of a filter. In my example, I maxed out the timeliness  regularization parameter to .3. Fortunately, no optimization of any parameter was needed in this example, as the performance was spiffy enough nearly right after gauging the timeliness parameter
regularization parameter to .3. Fortunately, no optimization of any parameter was needed in this example, as the performance was spiffy enough nearly right after gauging the timeliness parameter 
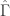 for both the sets of explanatory log-return data and Figure 4 depicts the coefficients for the filter. Notice that in the coefficients plot, much more weight is being assigned to past values of the log-return data with extreme (min and max values) at around lags 15 and 30 for the GOOG coefficients (blue-ish line). The coefficients are also quite smooth due to the slight amount of smooth regularization imposed.
for both the sets of explanatory log-return data and Figure 4 depicts the coefficients for the filter. Notice that in the coefficients plot, much more weight is being assigned to past values of the log-return data with extreme (min and max values) at around lags 15 and 30 for the GOOG coefficients (blue-ish line). The coefficients are also quite smooth due to the slight amount of smooth regularization imposed.

 is highly dependent on the data and should be located through a priori investigations (as I did above, without the additional bandpass).
is highly dependent on the data and should be located through a priori investigations (as I did above, without the additional bandpass).
 . The largest of these peaks will be defined from here on out as the principal spectral peak (PSP). Figure 6 shows an example of an averaged periodogram of the log-return for GOOG and AAPL with the PSP indicated. You might note that there exists a much larger spectral peak located at
. The largest of these peaks will be defined from here on out as the principal spectral peak (PSP). Figure 6 shows an example of an averaged periodogram of the log-return for GOOG and AAPL with the PSP indicated. You might note that there exists a much larger spectral peak located at  , but no need to worry about that one (unless you really enjoy transaction costs). I locate this PSP as a starting point for where I want my signal to trade.
, but no need to worry about that one (unless you really enjoy transaction costs). I locate this PSP as a starting point for where I want my signal to trade.
![[.49,.65]](https://s0.wp.com/latex.php?latex=%5B.49%2C.65%5D&bg=ffffff&fg=323232&s=0&c=20201002) with the PSP directly under it. I then optimized the regularization controls in-sample (a feature I haven’t discussed yet) and slightly tweaked the timeliness parameter (ended up setting it to 3) and my result (drumroll…) is shown in Figure 6.
with the PSP directly under it. I then optimized the regularization controls in-sample (a feature I haven’t discussed yet) and slightly tweaked the timeliness parameter (ended up setting it to 3) and my result (drumroll…) is shown in Figure 6.
![[.51, .68]](https://s0.wp.com/latex.php?latex=%5B.51%2C+.68%5D&bg=ffffff&fg=323232&s=0&c=20201002) , with the PSP still underneath the bandpass, but now catching on to a few more higher frequencies then before. I also slightly increased the length of the filter to see if that had any affect. After optimizing on the timeliness parameter
, with the PSP still underneath the bandpass, but now catching on to a few more higher frequencies then before. I also slightly increased the length of the filter to see if that had any affect. After optimizing on the timeliness parameter 



![(\omega_0, \omega_1) \subset [0,\pi]](https://s0.wp.com/latex.php?latex=%28%5Comega_0%2C+%5Comega_1%29+%5Csubset+%5B0%2C%5Cpi%5D&bg=ffffff&fg=323232&s=0&c=20201002) where
where  . We can introduce a constraint on the filter coefficients so as to impose a vanishing time-shift at frequency zero. As Wildi says on page 24 of the Elements paper: “A vanishing time-shift is highly desirable because turning-points in the filtered series are concomitant with turning-points in the original data.” In fact, we can take this a step further and even impose an arbitrary time-shift with the value
. We can introduce a constraint on the filter coefficients so as to impose a vanishing time-shift at frequency zero. As Wildi says on page 24 of the Elements paper: “A vanishing time-shift is highly desirable because turning-points in the filtered series are concomitant with turning-points in the original data.” In fact, we can take this a step further and even impose an arbitrary time-shift with the value  at frequency zero, where
at frequency zero, where  at zero is
at zero is  , which implies
, which implies  .
. , which is not a very frequent trading frequency, but has its benefits, as we’ll see. The preliminary metric space was constructed by an in-sample period using the daily log-returns of GOOG and AAPL and AAPL as my target is from 6-4-2011 to 9-25-2012, nearly 16 months of data. Thus we mention that the in-sample includes many important news events from Apple Inc. such as the announcement of the iPad mini, the iPhone 4S and 5, and the unfortunate sad passing of Steve Jobs. I then proceeded to bend the preliminary metric space with a heavy dosage of regularization, but only a tablespoon of customization¹. Finally, I set the time-shift constraint and applied my optimization routine in iMetrica to find the value
, which is not a very frequent trading frequency, but has its benefits, as we’ll see. The preliminary metric space was constructed by an in-sample period using the daily log-returns of GOOG and AAPL and AAPL as my target is from 6-4-2011 to 9-25-2012, nearly 16 months of data. Thus we mention that the in-sample includes many important news events from Apple Inc. such as the announcement of the iPad mini, the iPhone 4S and 5, and the unfortunate sad passing of Steve Jobs. I then proceeded to bend the preliminary metric space with a heavy dosage of regularization, but only a tablespoon of customization¹. Finally, I set the time-shift constraint and applied my optimization routine in iMetrica to find the value 



 indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.
indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.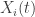 for
for  series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data
series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data 


