Overview
MDFA-DeepLearning is a library for building machine learning applications on large numbers of multivariate time series data, with a heavy emphasis on noisy (non)stationary data. The goal of MDFA-DeepLearning is to learn underlying patterns, signals, and regimes in multivariate time series and to detect, predict, or forecast them in real-time with the aid of both a real-time feature extraction system based on the multivariate direct filter approach (MDFA) and deep recurrent neural networks (RNN). The feature extraction system utilizes the MDFA-Toolkit to construct K multivariate signals in real-time (the features) where each of the K features targets a certain frequency range in the underlying time series. Furthermore, each (or some) of these features can also be forecasted multiple steps ahead, or smoothed, creating many possibilities of signal or regime learning in time series.
For the deep learning components, in this package we focus on two network structures, namely a recurrent weighted average network (RWA Ostmeyer and Cowell) and a standard long-short term memory network. The RWA cell is a type of RNN cell that computes a recurrent weighted average over every past processing timestep, unlike standard RNN cells which only process information from previous timesteps.
The overall general architecture of the proposed network is given in Figure 1 in the case of an RWA network, which we will discuss in more detail below. For a given sequence of N multivariate time series values which have been transformed appropriately to a stationary sequence, which we denote Y_1, Y_2, …, Y_N, a real-time feature extraction process is applied at each observation which is then used as input to an RWA (or LSTM) network, where the univariate output is a targeted signal value (regression) or a regime value (classification)..

Figure 1: Proposed network design using RWA cells to learn form the real-time feature extractor. The Y_t values are the (multivariate) transformed time series values, and the S_t are univariate outputs describing a target signal or regime
Why Use MDFA-DeepLearning
One might want to develop predictive models in multivariate time series data using MDFA-DeepLearning if the time series exhibit any of the following properties:
- High-Dimensionality (many (un)correlated nonstationary time series)
- Difficult to forecast using traditional model-based methods (VARIMA/GARCH) or traditional deep learning methods (RNN/LSTM, component decomposition, etc)
- Emphasis needed on out-of-sample real-time signal extraction and forecasting
- Regime changing in the underlying dynamics (or data generating process) of the time series is a common occurrence
The MDFA-DeepLearning approach differs from most machine learning methods in time series analysis in that an emphasis on real-time feature extraction is utilized where the features extractors are build using the multivariate direct filter approach. The motivation behind this coupling of MDFA with machine learning is that, while many time series decomposition methodologies exist (from empirical mode decomposition to stochastic component analysis methods), all of these rely on either in-sample decompositions on historical data (useless for future data), and/or assumptions about the boundary values, neither of which are attractive when fast, real-time out-of-sample predictions are the emphasis. Furthermore, simply applying standard recurrent neural networks for step-ahead forecasting or signal extraction directly on the original noisy data is a useless exercise – the recurrent networks typically will only learn noise, producing signals and forecasts of little to no value (in most cases, the latter).
As mentioned, the back-end used for the novel feature extraction is the multivariate direct filter approach (MDFA), and is used to extract both local (higher-frequency) and global (low-frequency) features in real-time, out-of-sample, and output these features in a multivariate time series as inputs into an RWA or LSTM recurrent neural network. Thus the package is divided into essentially four different components which all need to be defined properly in order to produce predictive models for time series data:
- Labeling interface
- Feature extractors
- DataSetIterator interface
- Learning interface
Labeling interface
The package includes an interface for labeling time series. The labeling process takes segments of historical data, and labels each time series observation in some manner. There are three types of labels that can be used:
- Observational labeling: every time series observation is labeled by a signal value (for example a target value computed by a symmetric target filter). This is sequence-to-sequence labeling for time series regression.
- Fixed Period labeling: every period (day, week, etc) is labeled, typically by a one-hot vector. This is sequence-to-value labeling. The end of the period is labeled and the rest of the values are not (masked by nonvalues in the code).
- Regime labeling: every value in a specific regime is labeled, either by a one-hot vector (for example, long (1,0) short (0,1) neutral (0,0), or trend (1,0) and mean-reverting (0,1)). This is another example of sequence-to-sequence, but using one-hot vectors and now in the form of sequence classification.
Other labeling strategies can certainly be used, but these are the three most common. We will give an outline on how to create a custom labeling strategy in a future article.
Feature Extractors
The package contains a feature extraction class called MDFAFeatureExtraction which, when instantiated, is used as the input to the a DataSetIterator. The MDFAFeatureExtraction contains a default automated feature extraction builder where a value of K is given as the number of features and a lag to indicate smoothing or forecasting steps-ahead.
One application of the MDFA feature extraction tool is to decompose a multivariate time series into K components in real-time which are close to being “orthogonal”, meaning in this sense that the frequency information from each of the components are relatively disjoint. A precise mathematical formulation of this property and examples of the MDFAFeatureExtraction to follow. Another example used for turning-point detection in trends is to decompose the multivariate series into K number of low-frequency components with different speeds and forecast/smoothing characteristics.
DataSetIterator
The DataSetIterator is an interface for ND4J that handles fast N-d array manipulation akin to numpy in Python. More specifically, the DataSetIterator handles traversing through a dataset and preparing data for a recurrent neural network. Our datasets in this package are outputs from the TimeSeries through the MDFAFeatureExtraction objects which then become the input to the RNN network. The DataSetIterator also performs the labeling and how output will be arranged. Thus it is essentially the communication from the underlying time series to the extraction process and then how it is treated as input and output to the RNN. In the package, we have designed two examples of DataSetIterators, one for regression and one for classification, that will be described in more detail in a later article.
Learning interface
Finally, the learning interface is where the final network is defined, all the parameters of the network, the activation and loss functions, and number/type of layers (LSTM, FeedForward, etc). The underlying computational framework for this component uses DeepLearning4J.
Requirements and Example
MDFA-DeepLearning requires both the MDFA-Toolkit package for constructing the time series feature extractors and the Eclipse Deeplearning4j (dl4j) library for the deep recurrent neural network constructors. The dl4j library is freely available at github.com/deeplearning4j, but is included in the build of this package using Gradle as the dependency management tool.
The back-end for the dl4j package will depend on your computational hardware, but is available on a local native basis using CPUs, or can take advantage of GPUs using CUDA libraries (CUDA 8.0 was used to test current version of MDFA-DeepLearnng). In this package I have included a reference to both versions (assuming a standard linux64 architecture).
The back-end used for the novel feature extraction technique, as mentioned, is the MDFA-Toolkit (available here), which will run on the ND4J package. The feature extraction begins by defining K MDFA objects, called MDFABase from the MDFA-Toolkit, with the fixed parameters set for each MDFA object. For example, here we define K=4 MDFABase objects, that will be used to extract different types of trends at different speeds in a fractionally differenced time series. Please refer to the MDFA-Toolkit documentation for more information on the definition of each MDFA parameter.
MDFABase[] anyMDFAs = new MDFABase[4]; anyMDFAs[0] = (new MDFABase()).setLowpassCutoff(Math.PI/8.0) .setI1(1) .setSmooth(.2) .setLag(-3) .setLambda(2.0) .setAlpha(2.0) .setFilterLength(5); anyMDFAs[1] = (new MDFABase()).setLowpassCutoff(Math.PI/10.0) .setLag(-2) .setAlpha(2.0) .setFilterLength(5); anyMDFAs[2] = (new MDFABase()).setLowpassCutoff(Math.PI/4.0) .setDecayStart(.1) .setDecayStrength(.2) .setLag(-1) .setFilterLength(5); anyMDFAs[3] = (new MDFABase()).setLowpassCutoff(Math.PI/14.0) .setSmooth(.2) .setDecayStart(.1) .setDecayStrength(.1) .setFilterLength(5);
More concrete, in-depth step by step examples and tutorials will be given in the source code on github and in this blog, but here we will just give a brief overview on an example main program using these features.
/* Define the .csv data file from where we built train/test dataIterators */
String[] dataFiles = new String[]{"AAPL.daily.csv"};
/* Information about the .csv timeseries file */
TimeSeriesFile fileInfo = new TimeSeriesFile("yyyy-MM-dd", "Index", "Open");
/* Define network parameters */
int miniBatchSize = 100;
int totalTrainExamples = 1500;
int totalTestExamples = 300;
int timeStepLength = 60;
int nHiddenLayers = 2;
int nHidden = 216;
int nEpochs = 400;
int seed = 123;
int iterations = 40;
double learningRate = .001;
double gradientNormThreshold = 10.0;
IUpdater updater = new Nesterovs(learningRate, .4);
/* Instantiate Feature Extractors as an array of MDFABase objects */
MDFAFeatureExtraction features = new MDFAFeatureExtraction(anyMDFAs);
/* Instantiate a new RecurrentMdfaRegression network using the features defined above */
RecurrentMdfaRegression myNet = new RecurrentMdfaRegression(features);
/* Set the data and the DataIterator parameters */
myNet.setTrainingTestData(dataFiles, fileInfo, miniBatchSize, totalTrainExamples, totalTestExamples, timeStepLength);
/* Usually a good idea to normalize the data */
myNet.normalizeData();
/* Build the LSTM (default network) layers */
myNet.buildNetworkLayers(nHiddenLayers, nHidden,
RecurrentMdfaRegression.setNeuralNetConfiguration(seed, iterations, learningRate, gradientNormThreshold, 0, updater));
/* An optional dl4j control panel to in the browser */
myNet.setupUserInterface();
/* Train on the number of Epochs */
myNet.train(nEpochs);
/* Print/plot results and stats */
myNet.printPredicitions();
myNet.plotBatches(10);
The main points here are that essentially three components need to be defined:
- The .csv time series data file from which the DataIterator will extract the time series data for both labeling and learning. Two data sets will be created from this, a train set and a test set. Referrencing to multiple files from which to extract training and test sets is also possible. In dl4j, training and test data is built in the form of a DataSetIterator interface (org.nd4j.linalg.dataset.api.iterator). In the package, we have defined a MDFADataSetIterator and a MDFARegressionDataSetIterator. More DataSetIterators for various applications will be added on an ongoing basis.
- The network RecurrentMdfaRegression is initiated, and needs to contain the feature signal extractors. Any set of feature extractors can be added, here we used the ones defined above as an example.
- Finally, the LSTM (or recurrent weighted average) network parameters need to be defined, this will then be used to construct the layers of the recurrent network.
With these three steps defined the network should be ready to train and test. The challenge is of course defining the feature extraction parameters. In later articles, we will give tips and tricks into what works best for what type of learning applications in large time series.




 as well as daily realized measures to yield better forecasting dynamics. The models have been shown to be endowed with the ability to not only track momentum in volatility, but also adjust for mean reversion effects as well as adjust quickly to structural breaks in the level of the volatility process. As the authors (Sheppard and Shephard, 2009) state in their original paper, the focus of these models is on predictive properties, rather than on non-parametric measurement of volatility. Furthermore, HEAVY models are much easier and more robust estimation wise than single source equations (GARCH, Stochastic Volatility) as they bring two sources of volatility information to identify a longer term component of volatility.
as well as daily realized measures to yield better forecasting dynamics. The models have been shown to be endowed with the ability to not only track momentum in volatility, but also adjust for mean reversion effects as well as adjust quickly to structural breaks in the level of the volatility process. As the authors (Sheppard and Shephard, 2009) state in their original paper, the focus of these models is on predictive properties, rather than on non-parametric measurement of volatility. Furthermore, HEAVY models are much easier and more robust estimation wise than single source equations (GARCH, Stochastic Volatility) as they bring two sources of volatility information to identify a longer term component of volatility. , where
, where  is the total amount of days in the sample we are working with. In the HEAVY model, we supplement information to the daily returns by a so-called realized measure of intraday volatility based on higher frequency data, such as second, minute or hourly data. The measures are called daily realized measures and we will denote them as
is the total amount of days in the sample we are working with. In the HEAVY model, we supplement information to the daily returns by a so-called realized measure of intraday volatility based on higher frequency data, such as second, minute or hourly data. The measures are called daily realized measures and we will denote them as 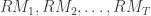 for the total number of days in the sample. We can think of these daily realized measures as an average of variance autocorrelations during a single day. They are supposed to provide a better snapshot of the ‘true’ volatility for a specific day
for the total number of days in the sample. We can think of these daily realized measures as an average of variance autocorrelations during a single day. They are supposed to provide a better snapshot of the ‘true’ volatility for a specific day  . Although there are numerous ways of computing a realized measure, the easiest is the realized variance computed as
. Although there are numerous ways of computing a realized measure, the easiest is the realized variance computed as  where
where  are the normalized times of trades on day
are the normalized times of trades on day 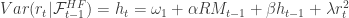

![\alpha, \omega_1 \geq 0, \beta \in [0,1]](https://s0.wp.com/latex.php?latex=%5Calpha%2C+%5Comega_1+%5Cgeq+0%2C+%5Cbeta+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002) and
and  with
with ![\lambda + \beta \in [0,1]](https://s0.wp.com/latex.php?latex=%5Clambda+%2B+%5Cbeta+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002) and
and ![\beta_R + \alpha_R \in [0,1]](https://s0.wp.com/latex.php?latex=%5Cbeta_R+%2B+%5Calpha_R+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=323232&s=0&c=20201002) . Here, the
. Here, the  denotes the high-frequency information from the previous day
denotes the high-frequency information from the previous day  . The first equation models the close-to-close conditional variance and is akin to a GARCH type model, whereas the second equation models the conditional expectation of the open-to-close variation.
. The first equation models the close-to-close conditional variance and is akin to a GARCH type model, whereas the second equation models the conditional expectation of the open-to-close variation. 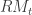 (akin to adding additional moving average parameters) or the conditional mean/variance variable (akin to adding autoregression parameters). One could also leave out the dependence on the squared returns
(akin to adding additional moving average parameters) or the conditional mean/variance variable (akin to adding autoregression parameters). One could also leave out the dependence on the squared returns  by setting
by setting 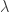 to zero, which is what the original others recommended. A third variation is adding yet another equation to the pack that models a realized measure that takes into account negative and positive momentum to yield possibly better forecasts as it tracks both losses and gains in the model. In this case, one would add the third component by introducing a new equation for a realized semivariance to parametrically model statistical leverage effects, where falls in asset prices are associated with increases in future volatility. With realized semivariance computed for the
to zero, which is what the original others recommended. A third variation is adding yet another equation to the pack that models a realized measure that takes into account negative and positive momentum to yield possibly better forecasts as it tracks both losses and gains in the model. In this case, one would add the third component by introducing a new equation for a realized semivariance to parametrically model statistical leverage effects, where falls in asset prices are associated with increases in future volatility. With realized semivariance computed for the  , the third equation becomes
, the third equation becomes
 and both positive.
and both positive. ,
,  variables. In the next line, the parameter values for the HEAVY model are initialized. These are the initial points that are utilized in the quasi-maximum likelihood optimization routine and can be set to any values that satisfy the model constraints. Here,
variables. In the next line, the parameter values for the HEAVY model are initialized. These are the initial points that are utilized in the quasi-maximum likelihood optimization routine and can be set to any values that satisfy the model constraints. Here, 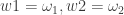 .
. and realized measures
and realized measures  and instead uses the unconditional means, leaving two less degrees of freedom in the optimization. See page 12 of the Shephard and Sheppard 2009 paper for a detailed explanation of the reparameterization. After setting the initial values, the data is set for the model by inputting the total number of observation
and instead uses the unconditional means, leaving two less degrees of freedom in the optimization. See page 12 of the Shephard and Sheppard 2009 paper for a detailed explanation of the reparameterization. After setting the initial values, the data is set for the model by inputting the total number of observation  values for 300 trading days from June 2011 to June 2012 of AAPL with the final 20 points being the forecasted values. Notice that the multistep ahead forecast shows momentum which is one of the attractive characteristics of the HEAVY models as mentioned in the original paper by Shephard and Sheppard.
values for 300 trading days from June 2011 to June 2012 of AAPL with the final 20 points being the forecasted values. Notice that the multistep ahead forecast shows momentum which is one of the attractive characteristics of the HEAVY models as mentioned in the original paper by Shephard and Sheppard.
 by simply using the filtered
by simply using the filtered  ,
, 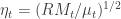 , leading to the innovations for the model for
, leading to the innovations for the model for  .
.

 ) that were simulated from a model with omega_1 = 0.05, omega_2 = 0.10, beta = 0.8 beta_R = 0.3, alpha = 0.02, alpha_R = 0.3 (the simulation was done in the Data Control Module).
) that were simulated from a model with omega_1 = 0.05, omega_2 = 0.10, beta = 0.8 beta_R = 0.3, alpha = 0.02, alpha_R = 0.3 (the simulation was done in the Data Control Module).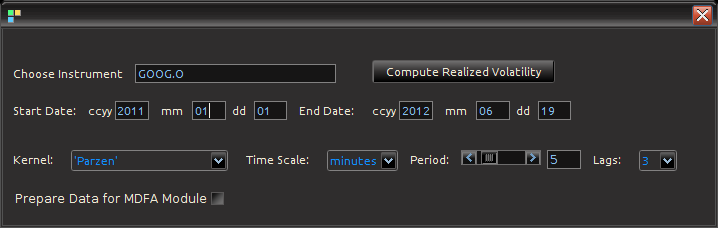
 2) The log-price of the asset, and 3) The realized volatility measure
2) The log-price of the asset, and 3) The realized volatility measure  . Once the Java-R highfrequency routine has finished computing the realized measures, the data sets are automatically available in the Data Control Module of iMetrica. From here, one can annualize the realized measures using the weight adjustments in the Data Control Module (see Figure 5). Once content with the weighting, the data can then be exported to the MDFA module or the BayesCronos module for estimating and forecasting the volatility of GOOG using HEAVY models.
. Once the Java-R highfrequency routine has finished computing the realized measures, the data sets are automatically available in the Data Control Module of iMetrica. From here, one can annualize the realized measures using the weight adjustments in the Data Control Module (see Figure 5). Once content with the weighting, the data can then be exported to the MDFA module or the BayesCronos module for estimating and forecasting the volatility of GOOG using HEAVY models.


 -th observation where n is some number much less than the total number of observations $latex N$ in the data set (say, one third the amount). The data sweep then computes the sliding window from
-th observation where n is some number much less than the total number of observations $latex N$ in the data set (say, one third the amount). The data sweep then computes the sliding window from 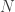 , in increments of one (see Figure 3). At each addition to the length of the window, the forecast is computed for up to 24 steps ahead. Of course, since the true time series data is known in the out-of-sample region of computation, we can compute the forecast error for up to
, in increments of one (see Figure 3). At each addition to the length of the window, the forecast is computed for up to 24 steps ahead. Of course, since the true time series data is known in the out-of-sample region of computation, we can compute the forecast error for up to 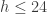 steps ahead and sum up these errors as
steps ahead and sum up these errors as  is the default). Lastly, select how many forecast steps you’d like to use in computing the forecast error (1-24). Once content with the settings, click the “Compute time series sweep” button and watch as the window span increases from
is the default). Lastly, select how many forecast steps you’d like to use in computing the forecast error (1-24). Once content with the settings, click the “Compute time series sweep” button and watch as the window span increases from  from a SARIMA model of dimension
from a SARIMA model of dimension 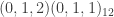 , namely a seasonal auto-regressive integrated moving-average process with two non-seasonal moving-average parameters, and one seasonal moving average parameter. The data sweep is performed on the simulated data with a forecast error horizon of length 23 using three different SARIMA models, (a)
, namely a seasonal auto-regressive integrated moving-average process with two non-seasonal moving-average parameters, and one seasonal moving average parameter. The data sweep is performed on the simulated data with a forecast error horizon of length 23 using three different SARIMA models, (a)  , (b)
, (b) 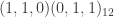 , (c)
, (c) 



