Introduction
Dynamic adaptive filtering is the method of updating a signal extraction process in real-time using newly provided information. This newly provided information is the next sequence of observed data, such as minute, hourly, or daily log-returns in a portfolio of financial assets, or a new set of weekly/monthly observations in a set of economic indicators. The goal is to improve the properties of the extracted signal with respect to a target (symmetric) filter and the output of past (old) signal values that are not performing as they should be (perhaps due to overfitting). In the multivariate direct filtering approach framework, it is an easily workable task to update the signal while only using the most recent information given. As a recently proposed idea by Marc Wildi last month, in this dynamic form of adaptive filtering we seek to update and improve a signal for a given multivariate time series information flow by computing a new set of filter coefficients to only a small window of the time series that features the latest observations. Instead of recomputing an entire new set of filter coefficients in-sample on the entire data set, we use a much smaller data set, say the latest 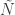
The new filter coefficients computed on this small window of new observations uses as input the filtered series from original ‘old’ filter. These new updated coefficients are then applied to the output of the old filter, leading to completely re-optimized filter coefficients and thus an optimized signal, eliminating any nasty effects due overfitting or signal ‘overshooting’ in the older filter, while at the same time utilizing new information. This approach is akin to, in a way, filtering within filtering: the idea of ‘smart’-filtering on previously filtered data for optimized control of the new signal being computed. It could also be thought of as filtering filtered data, a convolution of filters, updating the real-time signal, or, more generally, adaptive filtering. However you wish to think of it, the idea is that a new filter provides the necessary updating by correcting the signal output of the old filter, applied to data out-of-sample. A rather smart idea as we will see. With the coefficients of the old filter are kept fixed, we enter into the frequency world of the output of the ‘old’ filter to gain information on optimizing the new filter. Only the coefficients of the new updated filter are optimized, and can be optimized anytime new data becomes available. This adaptive process is dynamic in the sense that we require new information to stream in in order to update the new signal by constructing a new filter. Once the new filter is constructed, the newly adapted signal is built by first applying the old filter to the data to produce the initial (non-updated) signal from the new data, then the newly constructed filter optimized from this output is then applied to the ‘old’ signal producing the smarter updated signal. Below is an outline of this algorithm for dynamic adaptive filtering stripped of much of the mathematical details. A more in-depth look at the mathematical details of MDFA and this newly proposed adaptive filtering method can be found in section 10.1 of the Elements paper by Wildi.
Basic Algorithm
We begin with a target time series 

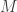



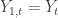
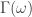
![\omega \in [0,\pi]](https://s0.wp.com/latex.php?latex=%5Comega+%5Cin+%5B0%2C%5Cpi%5D&bg=ffffff&fg=323232&s=0&c=20201002)

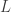
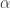
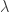
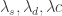




Now suppose we have new information flowing. With each new observation in our explanatory series 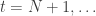








Dynamic Adaptive Filtering Interface in iMetrica
The adaptive filtering capabilities in iMetrica are controlled by an interface that allows for adjusting all aspects of the adaptive filter, including number of observations, filter length
- Data. A target time series and (optional)
observations for in-sample filter computation along with a stream of future information flow (i.e. an additional set of, say
series.
- An initial set of optimized filter coefficients
With these two prerequisites, we are now ready to test different dynamic adaptive filtering strategies. Figure 1 shows the MDFA module interface with time series data of a target series (shown in red) and four explanatory series (not plotted). Using the parameter configuration shown in Figure 1, an initial filter for computing the signal (green plot) that has been optimized in-sample on 300 observations of data and then applied to 30 out-of-sample observations (shown in the blue shaded region). As these final 30 observations of the signal have been produced using 30 out-of-sample observations, we can take note of its out-of-sample performance. Here, the performance of the signal has much room to improve. In this example, we use simulated data (conditionally heteroskedastic data generating process to emulate log-return type data) so that we are able to compare the computed updated signals with a high-order approximation of the target symmetric “perfect” signal (shown in gray in Figure 1).
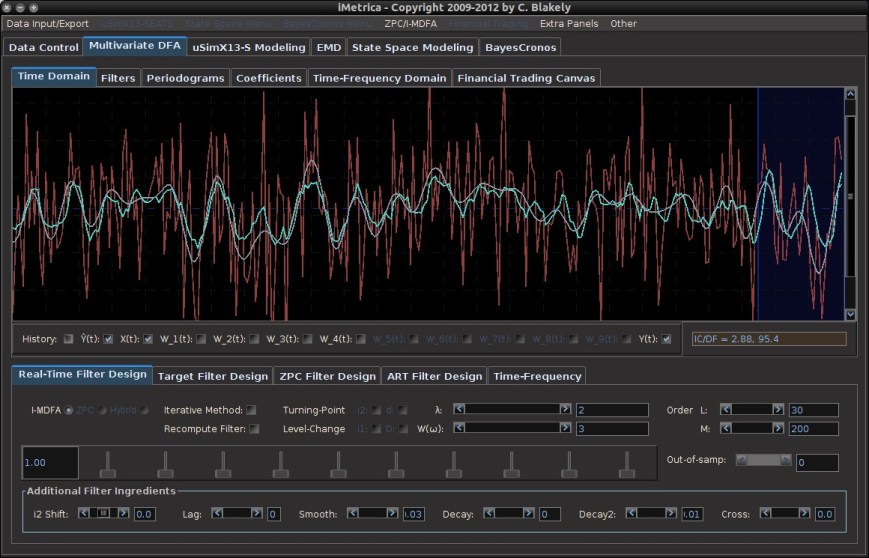
Figure 1. The original signal (green) built using 300 observations in-sample, and then applied to 30 out-of-sample observations. A high-order approximation to the target symmetric filter is plotted in gray. The blue shaded region is the region in which we wish to apply dynamic filter updating.
Now suppose we wish to improve performance of the signal in future out-of-sample observations by updating the filter coefficients to produce better smoothness, timeliness, and regularization properties. The first step is to ensure that the “Recompute Filter” option is not on (the checkbox in the Real-Time Filter Design panel. This should have been done already to produce the out-of-sample signal). Then go to the MDFA menu at the top of the software and click on “Adaptive Update”. This will pop open the Adaptive Filtering control panel from which we control everything in the new filter updating coefficients (see Figure 2).
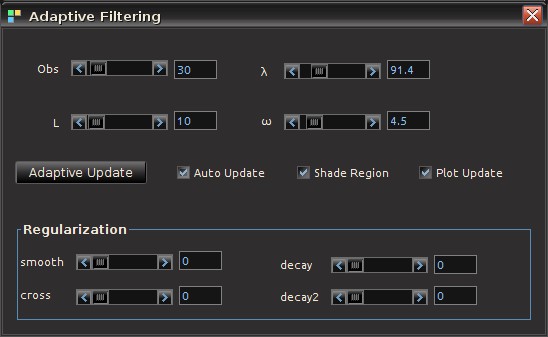
Figure 2. The panel interface for controlling every aspect of updating a filter in real-time.
The controls on the Adaptive Filtering panel are explained as follows:
- Obs. Sets the number of the latest observations used in the filter update. This is normally set to however many new observations out-of-sample have been streamed into the time series since the last filter computation. Although one can certainly include observations from the original in-sample period as well by simply setting Obs to a number higher than the number of recent out-of-sample observations. The minimum amount of observations is 10 and the maximum is the total length of the time series.
- L. Sets the length of the updating filter. Minimum is 5 and maximum is the number of observations minus 5.
- Adaptive Update. Once content with the settings of the update filter, press this button to compute the new filter and apply to the data. The results of the effects of the new filter will automatically appear in the main plotting canvas, specifically in the region of interest (shaded by blue, see blow).
- Auto Update. A check box that, if turned on, will automatically compute the new filter for any changes in the filter parameters and automatically plots the effects of the new filter in the main plotting canvas. This is a nice option to use when visually testing the output of the new filter as one can automatically see effects from any small changes to the parameter setting of the filter. This option also renders the “Adaptive Update” button obsolete.
- Shade Region. This check box, when activated, will shade the windowing region at the end of time series in which the updating is taking place. Provides a convenient way to pinpoint the exact region of interest for signal updating. The shaded region will appear in a dark blue shade (as shown in Figures 1, 4,6, and 7).
- Plot Updates. Clicking this checkbox on and off will plot the newly updated signal (on position) or the older signal (off position). This is a convenient feature as one is able to easily visually compare the new updated signal with the old signal to test for its effectiveness. If adding out-of-sample data and this feature is turned on, it will also apply the new updated filter coefficients to the new data as it comes in. If in the off position, it will only apply the ‘old’ filter coefficients.
- Regularization. All the regularization controls for the updating filter.
To update a signal in real-time, first select the number of observations
In this example, as previously mentioned, we computed the original signal in-sample using 300 observations and then applied the filter coefficients to 30 out-of-sample observations (this was produced by checking “Recompute Filter” off). This is plotted in Figure 4, with the blue shaded region highlighting the 30 latest observations, our region of interest. Notice a significant mangling of timeliness and signal amplification in the pass-band of the filter. This is due to bad properties of the filter coefficients. Not enough regularization was applied. Surely enough, the amplitude of the frequency response function in the original filter shows the overshooting in the pass-band (see Figure 5). To improve this signal, we apply an adaptive update by launching the Adaptive Update menu and configuring the new filter. Figure 6 shows the updated filter in the windowed region, where we chose a combination of timeliness and light regularization. There is a significant improvement in the timeliness of the signal. Any changes in the parameterization of the filter space is automatically computed and plotted on the canvas, a huge convenience as we can easily test different parameter configurations to easily identify the signal that satisfies the priorities of the user. In the final plot, Figure 7, we have chosen a configuration with a high amount of regularization to prevent overfitting. Compared with the previous two signals in the region of interest (Figures 4 and 6), we see an even greater mollification of the unwanted amplitude overshooting in the signal, without compromising with a lack of timeliness and smoothness properties. A high-order approximation to the targeted symmetric filter is also plotted in this example for comparison convenience (since the data is simulated, we know the future data, and hence the symmetric filter).
Tune in later this week for an example of Dynamic Adaptive Filtering applied to financial trading.
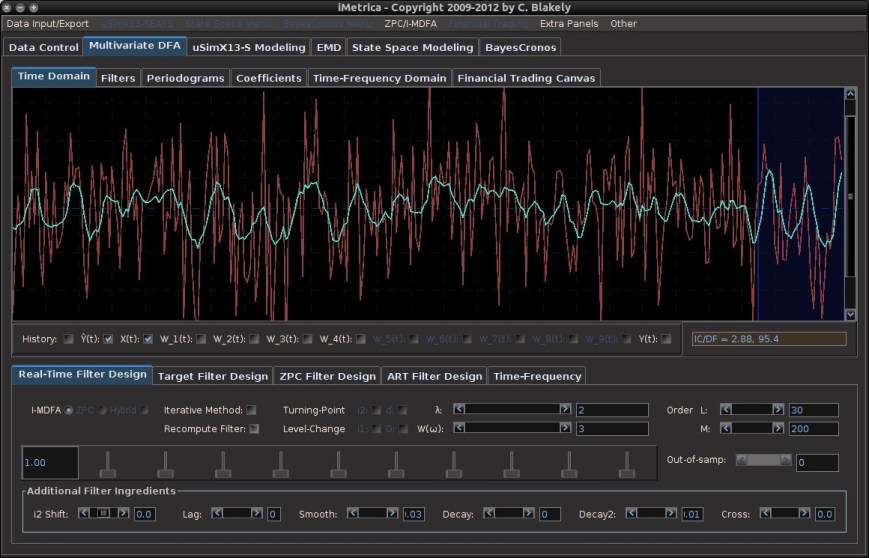
Figure 4. Plot of the signal out-of-sample before applying an update to the signal by allocating the 30 most recent out-of-sample observations and computing a new filter of length 10. The blue shaded region shows the updating region. Here the original old filter constructed in-sample has been applied to the 30 out-of-sample observations and we notice significant mangling of timeliness and signal amplification in the pass-band of the filter. This is due to bad properties of the filter coefficients. Not enough regularization was applied.
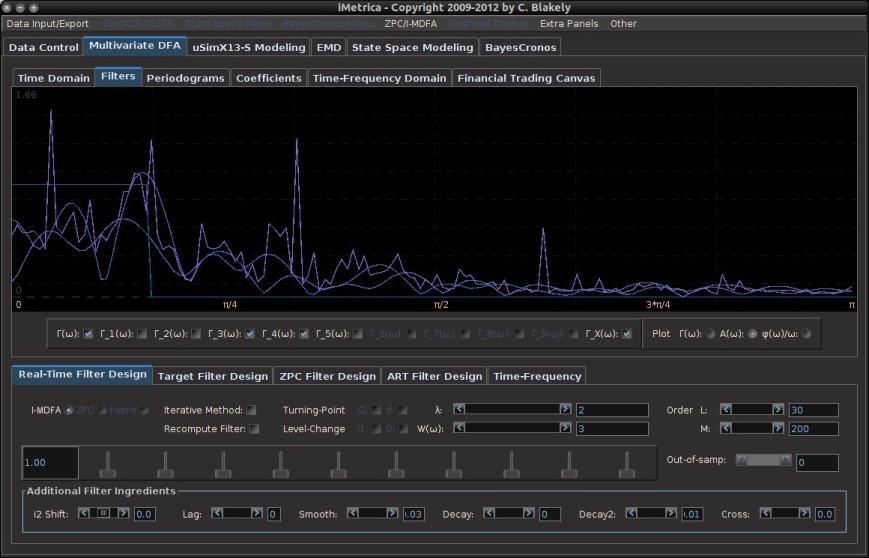
Figure 5. The overshooting in the pass-band of the frequency response function multivariate filter. The spikes above one in the pass-band indicate this and will most-likely produce overshooting in the signal out-of-sample.
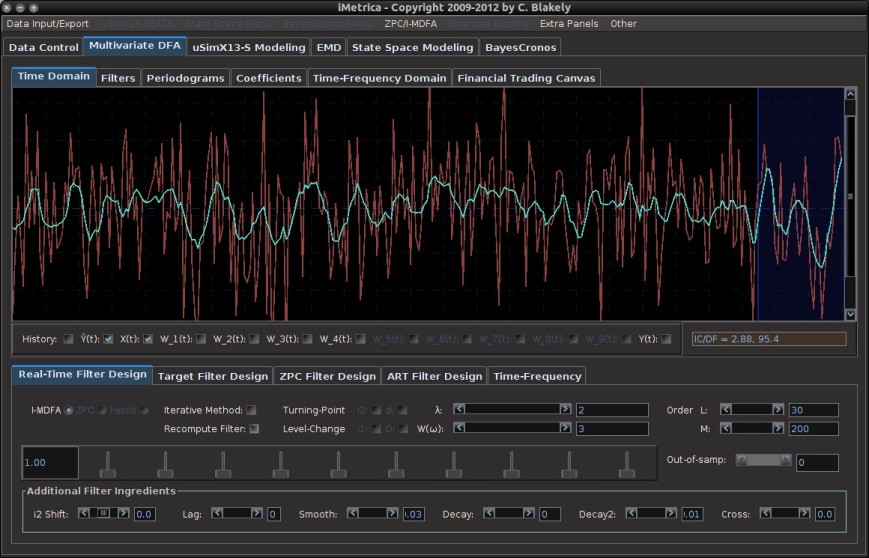
Figure 6 After filter updating in the final 30 observations. We chose the filter settings in the adaptive filter settings to improve timeliness with a small amount of smoothing. Furthermore, regularization (smooth, decay) was applied to ensure no overfitting. Notice how the properties of the signal are vastly improved (namely timeliness and little to no overshooting).
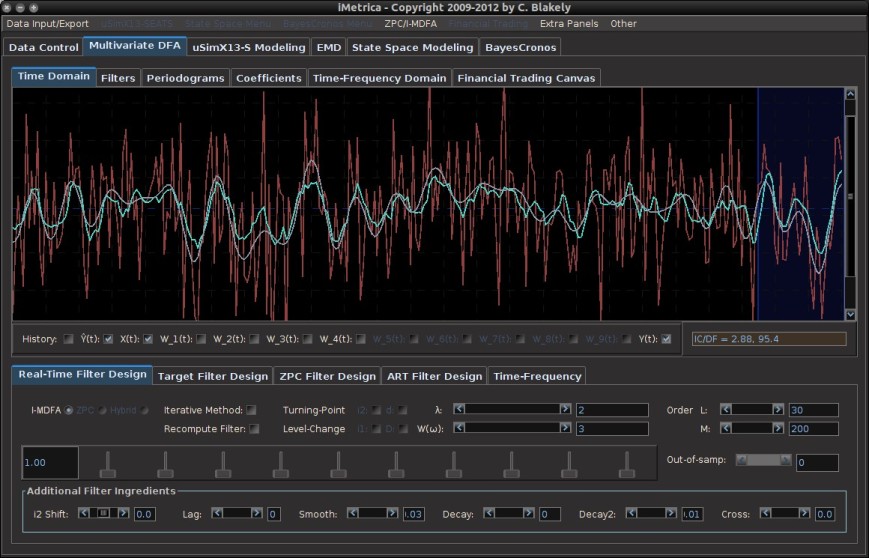
Figure 7. Not satisfied with the results of our filter update, we can easily adjust the parameters more to find a satisfying configuration. In this example, since the data is simulated, I’ve computed the symmetric filter to compare my results with the theoretically “perfect” filter. After further adjusting regularization parameters, I end up with this signal shown in the plot. Here, the gray signal is a high-order approximation to the target symmetric “perfect” signal. The result is a very close fit to the target signal with no overfitting.

Great intro to DAFs–probably the cleanest I’ve seen as it relates to financial time series from a trading perspective.
Would love to see iMetrica in action. The visuals put ggplot2 to shame! Is it available for download / trial?