
“Careful, we may be in a model…within a model.” (From an Inception movie poster.)
Have you ever seen the movie Inception and wondered, “Gee, wouldn’t it be neat if I could do all that fancy subconscious dream within a dream manipulation stuff”? Well now you can (in a metaphorical way) using MDFA and iMetrica. I explain how in this article.
Before I begin, may I first draw your attention to a brief introduction of the context in which I am speaking, and that is real-time signal extraction in (nonlinear, nonstationary) information flow. The principle goal of filtering and signal extraction in real-time data analysis for whatever purpose necessary (financial trading, risk analysis, real-time trend detection, seasonal adjustment) is to detect and pinpoint as timely as possible a desired sequence of events in an incoming flow of data observations. We emphasize that this detection should be fast, in that the desired signal, or sequence of events, should be so robust in its timeliness and accuracy so as to detect turning points or actions in targeted events as they happen, or even become so awesome that it manages to anticipate what will happen in the future. Of course, this is never an exact science nor even always possible (otherwise we’d all be billionaires right?) and thus we rely on creative ways to cope with the unknown.
We can also think of signal extraction in more abstract terms. Real-time signal extraction entails the construction of a ‘smart’ illusion, an alternative to reality, where reality in this context is a time series, the information flow, the raw data. This ‘smart’ illusion that is being constructed is the signal, the vital information that has been extracted from an abundance of “noise” embedded in the reality. And the signal must produce important underlying secrets to satisfy the needs of the user, the signal extractor. How these signals are extracted from reality is the grand challenge. How are they produced in a robust, fast, and feasible manner so as to be effective in the real-time flow of information? The answer is in MDFA, or in other words as I’ll describe in this article, penetrating the subconscious state of reality to gain access to hidden treasures.
After recently re-watching the Christopher Nolan opus entitled Inception starring Leonardo DiCaprio and what seems like most of the cast from the Dark Knight Trilogy, I began to see some similarities between the main concepts entertainingly presented in the movie (using some pimped-up CGI), and the mathematics of signal extraction using the multivariate direct filtering approach (MDFA). In this article I present some of these interesting parallels that I’ve managed to weave together. My ultimate goal with this article is to hopefully paint a vivid picture of some interesting details stemming from the mathematics of the direct filtering approach by using the parallels that I’ve contrived between the two. Afterwards, hopefully you’ll be on your way to entering the realm of ‘dreaming within dreaming’, and extracting pertinent hidden secrets embedded in a flurry of noise.
The film introduces a slick con man by the name of Cobb (played by DiCaprio), and his team of super well-dressed con artists with leather jackets and slicked back hair (the classic con man look right?). The catchy idea that resides in the premise of the film is that these aren’t ordinary con men: they have a unique way of manipulating reality: by entering the dreams (subconscious ) of their targets (or marks as they call them in the film) and manipulate their subconscious dream state under the goal of extracting a desired idea or hidden secret. Like any group of con men, they attempt to construct a false reality by creating a certain architecture and environment in the target’s dream. The effectiveness of this ‘heist’ to capture the desired signals in the dream relies on the quality of the architecture and environment of the dream.
So how does all this relate to the mathematics of the MDFA for signal extraction. My vision can be seen as follows. In manipulating the target’s subconscious , Cobb’s group basically involves a collection of four components. Each one can be associated with a mathematical concept embedded in the MDFA.
The Target – At the highest level, we have reality. The real world in which the characters, and the target (victim), live. The target victim has an abundance of hidden information among the large capacity of mostly noise, from which Cobb’s group wish to manipulate and extract a hidden secret, the signal. In the MDFA world, we can associate or represent the information flow, the time series on which we perform the signal extraction process as the target victim in the real world. This is the data that we see, the reality. This data of course is non-deterministic, namely we have no idea what the target victim has in mind for the future. The process of extracting the hidden thoughts or ideas from this target victim is akin to, in the MDFA world, the signal extraction process. The tools used to do the extracting are as follows.
The Extractor – The extractor is depicted in Inception as a master con man, a person who knows how to manipulate a subject (the target) in their subconscious dreaming world into revealing their deepest mental secrets. As the extractor’s goal is manipulation of the subconscious of a target to reveal a certain signal buried within reality, the extractor must transform the real-world conscious mental state of the target from reality into the dreaming subconscious world, by inducing a dream state. The multivariate direct filtering process of transforming the data (reality) into spectral frequency space (the subconscious ) via the Fourier transform to reveal the signal given the desired target data is metaphorically very similar to this process. The Inception extractor can be seen as being parallel to the process of transforming the data from reality into a subconscious world, the spectral frequency domain. It’s in this dreaming subconscious world, the frequency domain, where the real manipulation begins, using an architect.
The Architect – The Inception architect is the designer of the dream who constructs and builds the subconscious world into which the extractor brings the subject, or target. Just as the architect manipulates real world architecture and physics in order to create paradoxes like an endless staircase, folding buildings, smooth transitions from one place to another and other various phenomena otherwise impossible in the real world, the architect in the filtering world is the toolkit of filtering parameters that render the finite-dimensional metric space in which one constructs the filter coefficients to produce the desired signal. This includes the extraction rules (namely the symmetric target filter), customization for timeliness and speed, and regularization to warp and bend the finite dimensional filter metric space. Just as many different paths in the subconscious world toward the manipulation of the target subject exist and it is the architect’s job to create the optimal environment for extracting the desired signal, the architect in the direct filtering world uses the wide ranging set of filter parameters to bend and manipulate the metric space from which the filter coefficients are built and then used in the signal extraction process. Just as changing dynamics in the Inception real world (like the state of free-falling) will change the physics of the dreamt subconscious world (like floating in hotel elevator shafts while engaging in physical combat, Matrix style), changing dynamics in the information flow will alter the geometry of the consequent architecture being built for the filter. And furthermore, just as the dream architect must be highly skilled in order to manipulate correctly, the MDFA architect must be highly skilled in order to construct the appropriate space in which the optimal signal is extracted (hint hint, call me or Marc, we’re the extractors and architects).
Dream within a dream – As one of the more fascinating concepts introduced in Inception, the concept of the dream within a dream was also the main trick to their success in dream manipulation. Starting from reality, each level of the dreaming subconscious state can be further transposed into another level of subconscious , namely dreaming within a dream. The dream within a dream process puts you into a deeper state of dreaming. The deeper you go, the further one’s mind is removed from reality. This is where the subject of dynamic adaptive filtering comes into play (see my previous article here for an intro and basics to dynamic adaptive filtering in iMetrica). In the direct filtering world, dynamic adaptive filtering is akin to the dream within a dream concept: Once in a level of subconscious (the spectral frequency space in MDFA), and the architect has created the dream used for manipulation (the metric space for the filter coefficients), a new level of subconscious can then be entered by introducing a newly adapted metric space based on the information extracted from the first level of subconscious.
In the dream within a dream, time is the other factor. The deeper you go into a dream state, the faster your mind is able to imagine and perceive things within that dream state. For example, one minute in reality can seem like one hour in the dream state. At the next level of subconscious, at each level in the subconscious , the element of time speeds up exponentially. A similar analogy can be extracted (no pun intended) in the concept of dynamic adaptive filtering. In dynamic adaptive filtering, we first begin by extracting a signal with the desired filter architecture at the first level transformation from reality to the spectral frequency space. When new information is received and our extracted signal is not behaving how we desire, we can build a new filter architecture for manipulating the signal with the newly provided information, with all the filter parameters available to control the desired filter properties. We are inherently building a new updated filter architecture on top of the old filter architecture, and consequently building a new signal from the output of the old signal by correcting (manipulating) this old signal toward our desired goals. This is akin to the dream within a dream concept. And just like the idea of time passing much faster at each subconscious level, the effects of filter parameters for controlling regularization and speed occur at a much faster rate since we are dealing with less information, a much shorter time frame (namely the newly arrived information) at each subsequent filtering level. One can even continue down the levels of subconscious, building a new architecture on top of the previous architecture, continuously using the newly provided information at each level to build the next level of subconsciousness; dream within a dream within a dream.
To summarize these analogies, I’ll be adding a graphic soon to this article that explains in a more succinct manner these parallels described above between Inception and MDFA. In the meantime, here are the temporary replacements.

Haters gonna hate… extractors gonna extract.

Nolan, why you leavin’ Leo out?
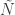 observations on which the older filter was applied out-of-sample which is much less than the total number of observations in the time series.
observations on which the older filter was applied out-of-sample which is much less than the total number of observations in the time series. ,
,  from which we wish to extract a signal, and along with it a set of
from which we wish to extract a signal, and along with it a set of 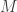 explanatory time series
explanatory time series  ,
,  ,
,  that may help in describing the dynamics of our target time series
that may help in describing the dynamics of our target time series 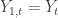 so that our target time series is included in the explanatory time series set, which makes sense since it is the only known time series to perfectly describe itself (however, not in every signal extraction applications is this a good idea. See for example the GDP filtering work of Wildi
so that our target time series is included in the explanatory time series set, which makes sense since it is the only known time series to perfectly describe itself (however, not in every signal extraction applications is this a good idea. See for example the GDP filtering work of Wildi 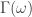 , that lives on the frequency domain
, that lives on the frequency domain ![\omega \in [0,\pi]](https://s0.wp.com/latex.php?latex=%5Comega+%5Cin+%5B0%2C%5Cpi%5D&bg=ffffff&fg=323232&s=0&c=20201002) . We define the architecture of the filter metric space for the initial signal extraction by the set of parameters
. We define the architecture of the filter metric space for the initial signal extraction by the set of parameters  , where
, where 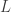 is the desired length of the filter,
is the desired length of the filter, 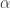 and
and 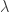 are the smoothness and timeliness customization controls, and
are the smoothness and timeliness customization controls, and 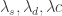 are the regularization parameters for smooth, decay, and cross, respectively. Once the filter is computed, we obtain a collection of filter coefficients
are the regularization parameters for smooth, decay, and cross, respectively. Once the filter is computed, we obtain a collection of filter coefficients  ,
,  for each explanatory time series
for each explanatory time series  ,
,  is then produced by applying the filter coefficients on each respective explanatory series.
is then produced by applying the filter coefficients on each respective explanatory series.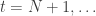 , we can apply the filter coefficients
, we can apply the filter coefficients  to
to  , we wish to update our signal to include this new information. Instead of recomputing the entire filter for the
, we wish to update our signal to include this new information. Instead of recomputing the entire filter for the  , a smarter idea recently proposed last month by Wildi in his MDFA blog is to use the output produced by applying each individual filter coefficient set
, a smarter idea recently proposed last month by Wildi in his MDFA blog is to use the output produced by applying each individual filter coefficient set  . We thus create a new set of
. We thus create a new set of  ,
,  and thus the filtered explanatory data series become the input to the MDFA solver, where we now solve for a new set of filter coefficients
and thus the filtered explanatory data series become the input to the MDFA solver, where we now solve for a new set of filter coefficients  to be applied on the output of the old filter of the new incoming data. In this new filter construction, we build a new architecture for the signal extraction, where a whole new set of parameters can be used
to be applied on the output of the old filter of the new incoming data. In this new filter construction, we build a new architecture for the signal extraction, where a whole new set of parameters can be used 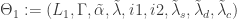 . This is the main idea behind this dynamic adaptive filtering process: we are building a signal extraction architecture within another signal extraction architecture since we are basing this new update design on previous signal extraction performance. Furthermore, since a much shorter span of observations, namely
. This is the main idea behind this dynamic adaptive filtering process: we are building a signal extraction architecture within another signal extraction architecture since we are basing this new update design on previous signal extraction performance. Furthermore, since a much shorter span of observations, namely  , is being used to construct the new filters, one of the advantages of this filter updating is that it is extremely fast, as well as being effective. As we will show in the next section of this article, all aspects of this dynamic adaptive filtering can be easily controlled, tested, and applied in the MDFA module of iMetrica using a new adaptive filtering control panel. One can control all aspects, from filter length to all the filter parameters in the new updated filter design, and then apply the results to out-of-sample data to compare performance.
, is being used to construct the new filters, one of the advantages of this filter updating is that it is extremely fast, as well as being effective. As we will show in the next section of this article, all aspects of this dynamic adaptive filtering can be easily controlled, tested, and applied in the MDFA module of iMetrica using a new adaptive filtering control panel. One can control all aspects, from filter length to all the filter parameters in the new updated filter design, and then apply the results to out-of-sample data to compare performance.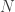 observations for in-sample filter computation along with a stream of future information flow (i.e. an additional set of, say
observations for in-sample filter computation along with a stream of future information flow (i.e. an additional set of, say 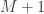 series.
series.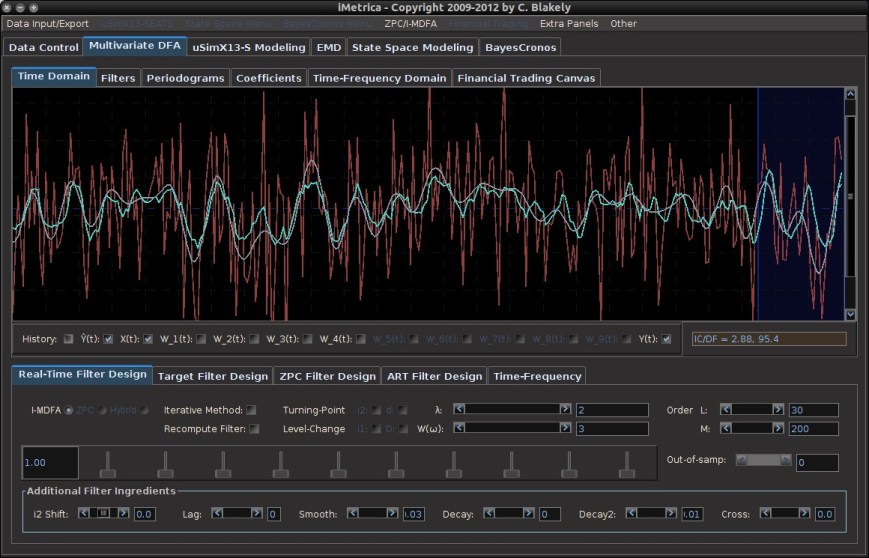
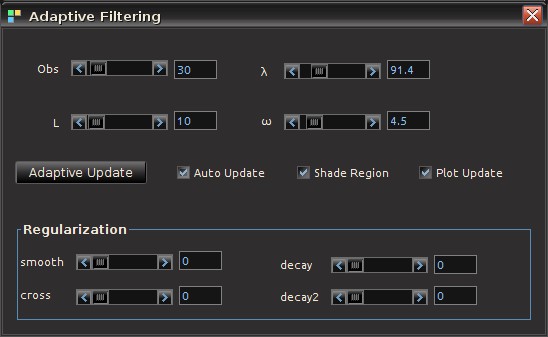
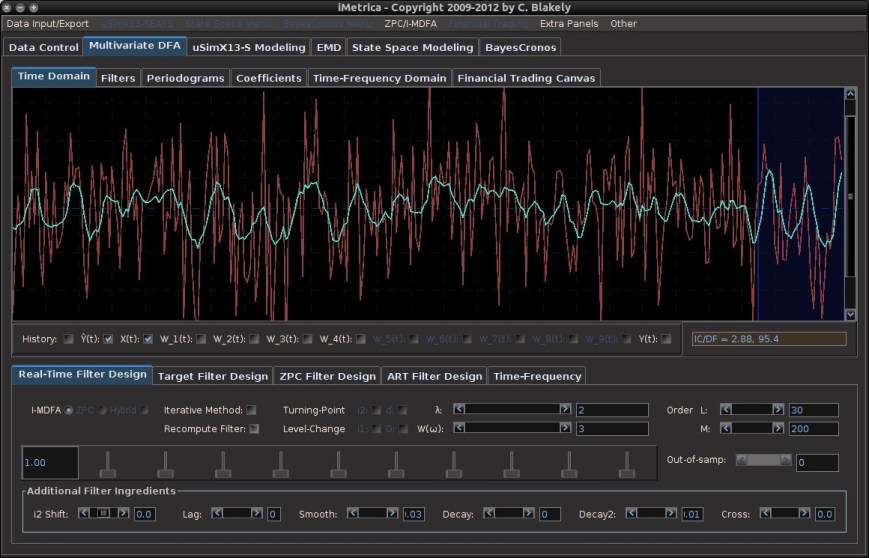
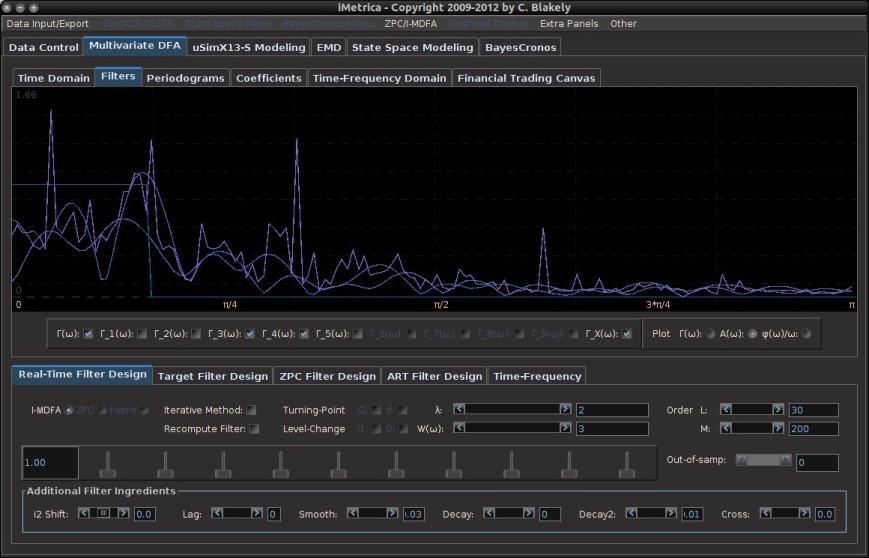
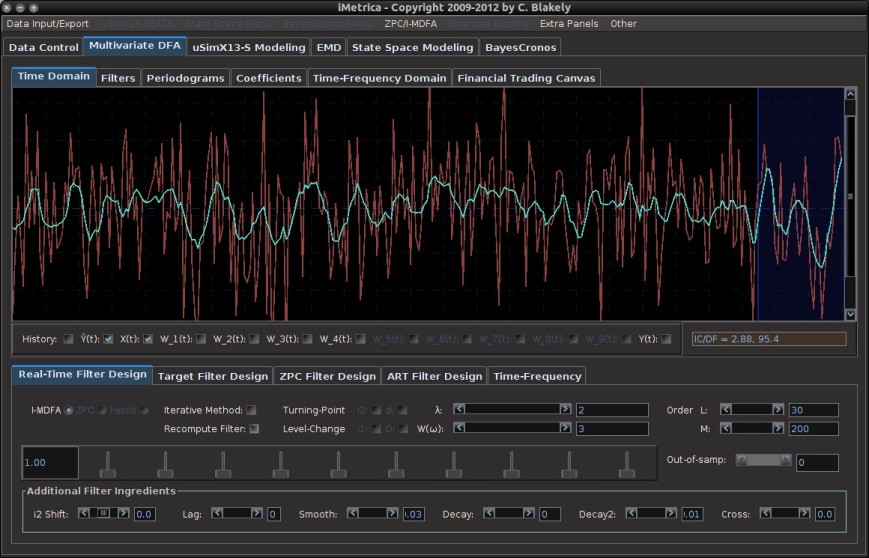
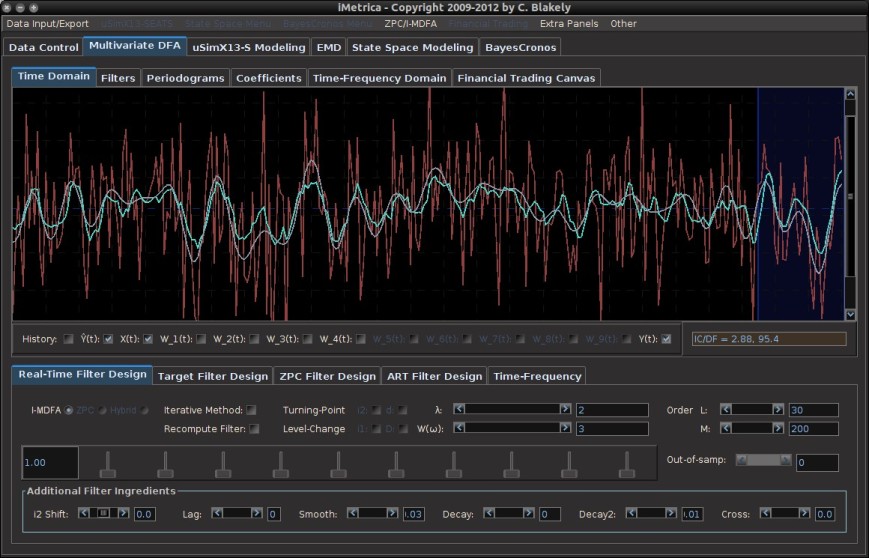





 (see Figure 2) and in the sliding scrollbar marked
(see Figure 2) and in the sliding scrollbar marked  option in the Real-Time Filter Design interface. To go further, one can even set the phase delay to an fixed value other than zero using the
option in the Real-Time Filter Design interface. To go further, one can even set the phase delay to an fixed value other than zero using the 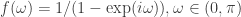 , which is the reciprocal of the differencing operator in the frequency domain. Since the Financial Trading platform in iMetrica strictly uses log-return financial time series to build trading signals, the use of this weighting function is in a sense a frequency-based “de-differencing” of the differenced data. In many cases, using the differencing weight provides better timeliness properties for the filter and thus the trading signal.
, which is the reciprocal of the differencing operator in the frequency domain. Since the Financial Trading platform in iMetrica strictly uses log-return financial time series to build trading signals, the use of this weighting function is in a sense a frequency-based “de-differencing” of the differenced data. In many cases, using the differencing weight provides better timeliness properties for the filter and thus the trading signal. in the scrollbar to any integer between -10 and 10 and the signal with the set lag applied is automatically computed. For negative lag values
in the scrollbar to any integer between -10 and 10 and the signal with the set lag applied is automatically computed. For negative lag values 

 indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.
indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.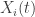 for
for  series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data
series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data 



