
Animation 1: Click to view animation. Periodogram and Various Frequency Intervals.

Animation 2: Click to view the animation. The in-sample performance of the trading signal for each frequency sweep shown in the animation above.
When constructing signals for buy/sell trades in financial data, one of the primary parameters that should be resolved before any other parameters are regarded is the trading frequency structure that regulates all the trades. The structure should be robust and consistent during all regimes of behavior for the given traded asset, namely during times of high volatility, sideways, or bull/bear markets. In the MDFA approach to building trading signals, the trading structure is mostly determined by the characteristics of the target transfer function, the 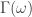 function that designates the areas of pass and stop-band frequencies in the data. As I argue in this article, I demonstrate that there exists an optimal frequency band in which the trades should be made, and the frequency band is intrinsic to the financial data being analyzed. Two assets do not necessarily share the same optimal frequency band. Needless to say, this frequency band is highly dependent on the frequency of the observations in the data (i.e. minute, hourly, daily) and the type of financial asset. Unfortunately, blindly seeking such an optimal trading frequency structure is a daunting and challenging task in general. Fortunately, I’ve built a few useful tools in the iMetrica financial trading platform to seamlessly navigate towards carving out the best (optimal or at least near optimal) trading frequency structure for any financial trading scenario. I show how it’s done in this article.
function that designates the areas of pass and stop-band frequencies in the data. As I argue in this article, I demonstrate that there exists an optimal frequency band in which the trades should be made, and the frequency band is intrinsic to the financial data being analyzed. Two assets do not necessarily share the same optimal frequency band. Needless to say, this frequency band is highly dependent on the frequency of the observations in the data (i.e. minute, hourly, daily) and the type of financial asset. Unfortunately, blindly seeking such an optimal trading frequency structure is a daunting and challenging task in general. Fortunately, I’ve built a few useful tools in the iMetrica financial trading platform to seamlessly navigate towards carving out the best (optimal or at least near optimal) trading frequency structure for any financial trading scenario. I show how it’s done in this article.
We first briefly summarize the procedure for building signals with a targeted range of frequencies in the (multivariate) direct filter approach, and then proceed to demonstrate how it is easily achieved in iMetrica. In order to construct signals of interest in any data set, a target transfer function must first be defined. This target filter transfer function defined on ![\omega \in [0,\pi]](https://s0.wp.com/latex.php?latex=%5Comega+%5Cin+%5B0%2C%5Cpi%5D&bg=ffffff&fg=323232&s=0&c=20201002) controls the frequency content of the output signal through the computation of the optimal filter coefficients. Defining
controls the frequency content of the output signal through the computation of the optimal filter coefficients. Defining 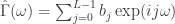 for some collection of filter coefficients
for some collection of filter coefficients  , recall that in the plain-vanilla (univariate) direct filter approach (for ‘quasi’ stationary data), we seek to find the
, recall that in the plain-vanilla (univariate) direct filter approach (for ‘quasi’ stationary data), we seek to find the 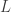 coefficients such that
coefficients such that  is minimized, where
is minimized, where  is a ‘smart’ weighting function that approximates the ‘true’ spectral density of the data (in general the periodogram of the data, or a function using the periodogram of the data). By defining as a function that takes on the value of one or less for a certain range of values in
is a ‘smart’ weighting function that approximates the ‘true’ spectral density of the data (in general the periodogram of the data, or a function using the periodogram of the data). By defining as a function that takes on the value of one or less for a certain range of values in ![[0,\pi]](https://s0.wp.com/latex.php?latex=%5B0%2C%5Cpi%5D&bg=ffffff&fg=323232&s=0&c=20201002) and zero elsewhere, we pinpoint exotic frequencies where we wish our filter to extract the features of the data. The characteristics of the generated output signal (after the resulting filter has been applied to the data) are those intrinsic to the selected frequencies in the data. The characteristics found at other frequencies are (in a perfect world) disregarded from the output signal. As we show in this article, the selection of the frequencies when defining provides the utmost in importance when building financial trading signals, as the optimal frequencies in regards to trading performance vary with every data set.
and zero elsewhere, we pinpoint exotic frequencies where we wish our filter to extract the features of the data. The characteristics of the generated output signal (after the resulting filter has been applied to the data) are those intrinsic to the selected frequencies in the data. The characteristics found at other frequencies are (in a perfect world) disregarded from the output signal. As we show in this article, the selection of the frequencies when defining provides the utmost in importance when building financial trading signals, as the optimal frequencies in regards to trading performance vary with every data set.
As mentioned, much emphasis should be applied to the construction of this target and finding the optimal one is not necessarily an easy task in general. With a plethora of other parameters that are involved in building a trading signal, such as customization and regularization (see my article on financial trading parameters), one could just simply select any arbitrary frequency range for and then proceed to optimize the other parameters until a winning trading signal is found. That is, of course, an option. But I’d like to be an advocate for carving out the proper frequency range that’s intrinsically optimal for the data set given, namely because I believe one exists, and secondly because once in the proper frequency range for the data, other parameters are much easier to optimize. So what kind of properties should this ‘optimal’ frequency range possess in regards to the trading signal?
- Consistency. Provides out-of-sample performance akin to in-sample performance.
- Optimality. Generates in-sample trade performance with rank coefficient above .90.
- Robustness. Insensitive to small changes in parameterization.
Most of these properties are obvious when first glancing at them, but are completely nontrivial to obtain. The third property tends to be overlooked when building efficient trading signals as one typically chooses a parameterization for a specific frequency band in the target , and then becomes over-confident and optimistic that the filter will provide consistent results out-of-sample. With a non-robust signal, small change in one of the customization parameters completely eradicates the effectiveness and optimality of the filter. An optimal frequency range should be much less sensitive to changes in the customization and regularization of the filter parameters. Namely, changing the smoothing parameter, say 50 percent in either direction, will have little effect on the in-sample performance of the filter, which in turn will produce a more robust signal.
To build a target transfer function , one has many options in the MDFA module of iMetrica. The approach that we will consider in this article is to define directly by indicating the frequency pass-band and stop-band structure directly. The simplest transfer functions are defined by two cutoff frequencies: a low cutoff frequency  and a high-cutoff frequency
and a high-cutoff frequency  . In the Target Filter Design control panel (see Figure 1), one can control every aspect of the target transfer function function, from different types of step functions, to more exotic options using modeling. For building financial trading signals, the Band-Pass option will be sufficient. The cutoff frequencies and are adjusted by simply modifying their values using the slider bars designated for each value, where three different ways of modifying the cutoff frequency values are available. The first is the direct designation of the value using the slider bar which goes between values of
. In the Target Filter Design control panel (see Figure 1), one can control every aspect of the target transfer function function, from different types of step functions, to more exotic options using modeling. For building financial trading signals, the Band-Pass option will be sufficient. The cutoff frequencies and are adjusted by simply modifying their values using the slider bars designated for each value, where three different ways of modifying the cutoff frequency values are available. The first is the direct designation of the value using the slider bar which goes between values of 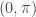 by changes of .01. The second method uses two different slider bars to change the values of the numerator
by changes of .01. The second method uses two different slider bars to change the values of the numerator  and denominator
and denominator  where and/or is written in fractional form
where and/or is written in fractional form  , a form commonly used for defining different cycles in the data. The third method is to simply type in the value of the cutoff in the designated text area and then press Enter on the keyboard, where the number must be a real number in the interval and entered in decimal form (i.e. 0.569, 1.349, etc). When the Auto checkbox is selected, the new direct filter and signal will be computed automatically when any changes to the target transfer function are made. This can be a quite useful tool for robustness verification, to see how small changes in the frequency content affect the output signal, and consequently the trading performance of the signal.
, a form commonly used for defining different cycles in the data. The third method is to simply type in the value of the cutoff in the designated text area and then press Enter on the keyboard, where the number must be a real number in the interval and entered in decimal form (i.e. 0.569, 1.349, etc). When the Auto checkbox is selected, the new direct filter and signal will be computed automatically when any changes to the target transfer function are made. This can be a quite useful tool for robustness verification, to see how small changes in the frequency content affect the output signal, and consequently the trading performance of the signal.
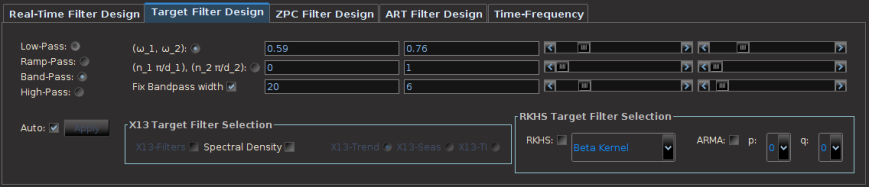
Figure 1: Target filter design panel.
Although cycling through multiple frequency ranges to find the optimal frequency bands for in-sample trading performance can be seamlessly accomplished by just sliding the scrollbars around (as shown in Animations 1 and 2 at the top of the page), there is a much easier way to achieve optimality (or near optimality) automatically thanks to a Financial Trading Optimization control panel featured in the Financial Trading menu at the top of the iMetrica interface. Once in the Financial Trading interface, optimization of both the customization parameters for timeliness and smoothness, along with optimization of the frequency bands can be accomplished by first launching the Trading Optimization panel (see Figure 2), and then selecting the optimization criteria desired (maximum return, minimum loss, maximum trade success ratio, maximum rank coefficient,… etc). To find the optimal customization parameters, simply select the optimization criteria from the drop-down menu, and then click either the Simulated Annealing button, or Grid Search button (as the name implies, ‘grid search’ simply creates a fine grid of customization values  and smoothing expweight
and smoothing expweight  and then chooses the maximal value after sweeping the entire grid – it takes a few seconds depending on the length of the filter. The method that I prefer for now). After the optimal parameters are found, the plotting canvas in the optimization panel paints a contour plot of the values found in order to give you an idea of the customization geometry, with all other parameterization values fixed. The frequency bandwidth of the target transfer function can then be optimized by a quick few millisecond grid search by selecting the checkbox Optimize bandwidth only. In this case the customization parameters are held fixed to their set values, and the optimization proceeds to only vary the frequency parameters. The values of the optimization function produced during the grid-search are then plotted on the optimization canvas to yield the structure from the frequency domain point-of-view. This can be helpful when comparing different frequency bands in building trading signals. It can also help in determining the robustness of the signal, by looking at the near neighboring values found at the optimal value.
and then chooses the maximal value after sweeping the entire grid – it takes a few seconds depending on the length of the filter. The method that I prefer for now). After the optimal parameters are found, the plotting canvas in the optimization panel paints a contour plot of the values found in order to give you an idea of the customization geometry, with all other parameterization values fixed. The frequency bandwidth of the target transfer function can then be optimized by a quick few millisecond grid search by selecting the checkbox Optimize bandwidth only. In this case the customization parameters are held fixed to their set values, and the optimization proceeds to only vary the frequency parameters. The values of the optimization function produced during the grid-search are then plotted on the optimization canvas to yield the structure from the frequency domain point-of-view. This can be helpful when comparing different frequency bands in building trading signals. It can also help in determining the robustness of the signal, by looking at the near neighboring values found at the optimal value.
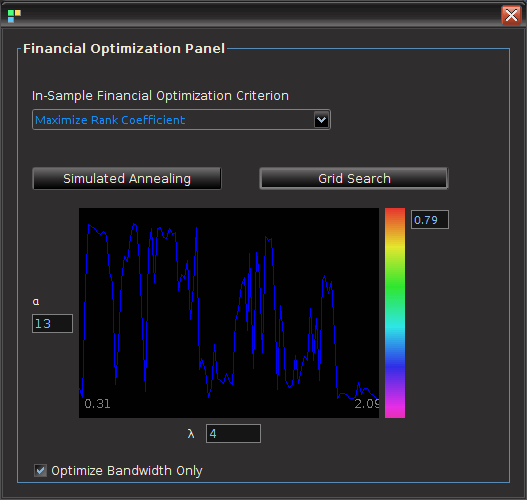
Figure 2: The financial trading optimization panel. Here the values of the optimization criteria are plotted for all the different frequency intervals. The interval with the maximum value is automatically chosen and then computed.
We give a full example of an actual trading scenario to show how this process works in selecting an optimal frequency range for a given set of market traded assets. The outline of my general step-by-step approach for seeking good trading filters goes as follows.
- Select the initial frequency band-pass by first initializing the
 interval to
interval to 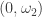 . Setting
. Setting  to .10-.15 is usually sufficient. Set the checkbox Fix-Bandpass width in order to secure the bandwidth of the filter.
to .10-.15 is usually sufficient. Set the checkbox Fix-Bandpass width in order to secure the bandwidth of the filter.
- In the optimization panel (Figure 2), click the checkbox Optimize Bandwidth only and then select the optimization criteria. In these examples, we choose to maximize the rank coefficient, as it tends to produce the best out-of-sample trading performance. Then tap the Grid Search button to find the frequency range with the maximum rank coefficient. This search takes a few milliseconds.
- With the initialization of the optimal bandwidth, the customization parameters can now be optimized by deselecting the Optimize Bandwidth only and then tapping the Grid Search button once more. Depending on the length of the filter and the number of addition explaining series, this search can take several seconds.
- Repeat steps 2 and 3 until a combination is found of customization and filter bandwidth that produces a rank coefficient above .90. Also, test the robustness of the trading signal by slightly adjusting the frequency range and the customization parameters by small changes. A robust signal shouldn’t change the trading statistics too much under slight parameter movement.
Once content with the in-sample trading statistics (the Trading Statistics panel is available from the Financial Trading Menu), the final step is to apply the filter to out-of-sample data and trade away. Provided that sufficient regularization parameters have been selected prior to the optimization (regularization selection is out of the scope of this article however) and the optimized trading frequency bandwidth was robust enough, the out-of-sample performance of the signal should perform akin to in-sample. If not, start over with different regularization parameters and filter length, or seek options using adaptive filtering (see my previous article on adaptive filtering).
In our example, we trade on the daily price of GOOG by using GOOG log-return data as the target data and first explanatory series, along with AAPL daily log-returns as the second explanatory series. After the four steps taken above, an optimal frequency range was found to be 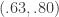 , where the in-sample period was from 6-3-2011 to 9-21-2012. The post-optimization of the filter, showing the MDFA trading interface, the in-sample trading statistics, and the trading optimization is shown in Figure 3. Here, the in-sample maximum rank coefficient was found to be at .96 (1.0 is the best, -1.0 is pitiful), where the trade success ratio is around 67 percent, a return-on-investment at 51 percent, and a maximum loss during the in-sample period at around 5 percent. Applying this filter out-of-sample on incoming data for 30 trading days, without any adjustments to the filter, we see that the performance of the signal was very much akin to the performance in-sample (see Figure 5). At the end of the 30 out-of-sample trading days after the in-sample period, the trading signal gives a 65 percent return for a total of a 14 percent return-on-investment in 30 trading days. During this period, there were 6 trades made (3 buys and 3 sell shorts), and 5 of them were successful (with a .1 percent transaction cost for any trade), which amounts to, on average, one trade per week.
, where the in-sample period was from 6-3-2011 to 9-21-2012. The post-optimization of the filter, showing the MDFA trading interface, the in-sample trading statistics, and the trading optimization is shown in Figure 3. Here, the in-sample maximum rank coefficient was found to be at .96 (1.0 is the best, -1.0 is pitiful), where the trade success ratio is around 67 percent, a return-on-investment at 51 percent, and a maximum loss during the in-sample period at around 5 percent. Applying this filter out-of-sample on incoming data for 30 trading days, without any adjustments to the filter, we see that the performance of the signal was very much akin to the performance in-sample (see Figure 5). At the end of the 30 out-of-sample trading days after the in-sample period, the trading signal gives a 65 percent return for a total of a 14 percent return-on-investment in 30 trading days. During this period, there were 6 trades made (3 buys and 3 sell shorts), and 5 of them were successful (with a .1 percent transaction cost for any trade), which amounts to, on average, one trade per week.
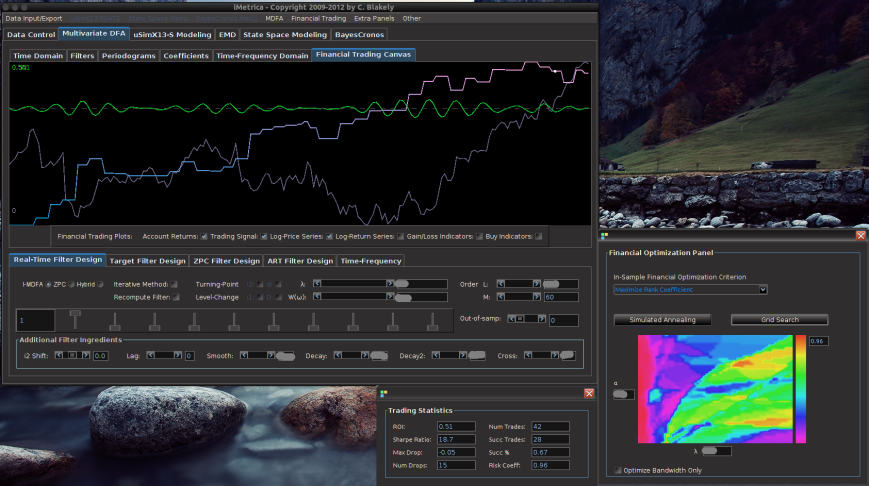
Figure 3. After in-sample optimization on both the customization and filter frequency band.

Figure 4: After applying the constructed filter on the next 30 days out-of-sample.
The other filter parameters (customization, regularization, and filter length ) have been blurred-out on purpose for obvious reasons. However, interested readers can e-mail me and I’ll send the optimal customization and regularization parameters, or maybe even just the filter coefficients themselves so you can apply them to data future GOOG and AAPL data and experiment.) We then apply the filter out-of-sample for 30 days and make trades based on the output of the trading signal. In Figure 4, the blue-to-pink line represents the performance of the trading account given by the percentage returns from each trade made over time. The grey line is the log-price of GOOG, and the green line is the trading signal constructed from the filter just built applied to the data. It signals a ‘buy’ when the signal moves above the zero line (the dotted line) and a sell (and short-sell) when below the line. Since the data are the daily log-returns at the end each market trading period, all trades are assumed to have been made near or at the end of market hours.
Notice how successful this chosen frequency range is during the times of highest volatility for Google being in this example the first 60 day period of the in-sample partition (roughly September-October 2011). This in-sample optimization ultimately helped the 30 days out-of-sample period where volatility increased again (with even an 8 percent drop on October 17th, 2012). Out of all the largest drops in the price of Google in both the in-sample and out-of-sample period, the signal was able to anticipate all of them due to the smart choice of the frequency band and then end up making profits by short-selling.
To summarize, during an out-of-sample period in which GOOG lost over 10 percent of their stock price, the optimized trading signal that was built in this example earned roughly 14 percent. We were able to accomplish this by investigating the properties of the behavior of different frequency intervals in regard to not only the optimization criteria, but also areas of robustness in both the values of the filter frequency intervals as well as customization controls (see the animations at the top of this article). This is mostly aided by the very efficient and fast (this is where the gnu-c language came in handy) financial trading optimization panel as well as the ability in iMetrica to make any changes to the filter parameters and instantaneously see the results. Again, feel free to contact me for the filter parameters that were found in the above example, the filter coefficients, or any questions you may have.
Happy New Year and Happy Extracting!








 (see Figure 2) and in the sliding scrollbar marked
(see Figure 2) and in the sliding scrollbar marked  option in the Real-Time Filter Design interface. To go further, one can even set the phase delay to an fixed value other than zero using the
option in the Real-Time Filter Design interface. To go further, one can even set the phase delay to an fixed value other than zero using the 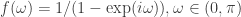 , which is the reciprocal of the differencing operator in the frequency domain. Since the Financial Trading platform in iMetrica strictly uses log-return financial time series to build trading signals, the use of this weighting function is in a sense a frequency-based “de-differencing” of the differenced data. In many cases, using the differencing weight provides better timeliness properties for the filter and thus the trading signal.
, which is the reciprocal of the differencing operator in the frequency domain. Since the Financial Trading platform in iMetrica strictly uses log-return financial time series to build trading signals, the use of this weighting function is in a sense a frequency-based “de-differencing” of the differenced data. In many cases, using the differencing weight provides better timeliness properties for the filter and thus the trading signal.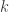 in the scrollbar to any integer between -10 and 10 and the signal with the set lag applied is automatically computed. For negative lag values
in the scrollbar to any integer between -10 and 10 and the signal with the set lag applied is automatically computed. For negative lag values 

 indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.
indicates a weighted aggregation of the data. To edit this, use the “Target Series” in 3. To delete all of the data stored in the data control module, simply press the “Delete” button. Careful, there’s no going back once deleted.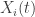 for
for  series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data
series). In modules that only deal with univariate time series data (the uSimX13, EMD, and State Space Modeling), the constructed target series is the series that gets exported for analysis. For the MDFA module, this is the series that is being filtered for constructing a signal, with the other time series acting as the explanatory time series. In the BayesCronos module, this target series is ignored and only the supporting time series data 


